
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 통계 쿼리 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://toplist.maxfit.vn team, along with other related topics such as: 통계 쿼리 통계 쿼리 예제, Oracle 통계 쿼리, MySQL 통계쿼리, SQL 통계 쿼리, 오라클 통계 쿼리 예제, 통계 SQL, 일자별 통계 쿼리, 오라클 월별 통계 쿼리
힘차게, 열심히 공대생 :: [SQL] SQL 쿼리문, 통계 데이터 내기
- Article author: thalals.tistory.com
- Reviews from users: 27090
 Ratings
Ratings - Top rated: 4.2
- Lowest rated: 1
- Summary of article content: Articles about 힘차게, 열심히 공대생 :: [SQL] SQL 쿼리문, 통계 데이터 내기 1) Group by : 범주의 통계내기 select name, count(*) from users group by name; group by name: name이라는 필드에서 동일한 값을 갖는 데이터를 … …
- Most searched keywords: Whether you are looking for 힘차게, 열심히 공대생 :: [SQL] SQL 쿼리문, 통계 데이터 내기 1) Group by : 범주의 통계내기 select name, count(*) from users group by name; group by name: name이라는 필드에서 동일한 값을 갖는 데이터를 … 1) Group by : 범주의 통계내기 select name, count(*) from users group by name; group by name: name이라는 필드에서 동일한 값을 갖는 데이터를 하나로 합쳐줍니다 select name, count(*): 이름과 count(*)..
- Table of Contents:
네비게이션
[SQL] SQL 쿼리문 통계 데이터 내기사이드바
검색
티스토리툴바
![힘차게, 열심히 공대생 :: [SQL] SQL 쿼리문, 통계 데이터 내기](https://t1.daumcdn.net/tistory_admin/static/images/openGraph/opengraph.png)
[MYSQL] 통계쿼리 with rollup
- Article author: allmana.tistory.com
- Reviews from users: 21769 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about [MYSQL] 통계쿼리 with rollup 간단하게 통계 쿼리 짜는 법에 대해 설명하려한다. product 란 테이블에 A,B,C 상품들에 대한 개수 데이터들이 들어있다. 이것에 대한 통계를 낼때 … …
- Most searched keywords: Whether you are looking for [MYSQL] 통계쿼리 with rollup 간단하게 통계 쿼리 짜는 법에 대해 설명하려한다. product 란 테이블에 A,B,C 상품들에 대한 개수 데이터들이 들어있다. 이것에 대한 통계를 낼때 … 간단하게 통계 쿼리 짜는 법에 대해 설명하려한다. product 란 테이블에 A,B,C 상품들에 대한 개수 데이터들이 들어있다. 이것에 대한 통계를 낼때 기본적으로 name을 group by 해주고 cnt(개수)는 SUM 을 해주..
- Table of Contents:
티스토리툴바
![[MYSQL] 통계쿼리 with rollup](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fcj1Ji0%2FbtqEcnQbfRE%2FckmweXx7W14TEculyPwJRK%2Fimg.png)
쿼리 통계 | Cloud Spanner | Google Cloud
- Article author: cloud.google.com
- Reviews from users: 16699 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about 쿼리 통계 | Cloud Spanner | Google Cloud 참고 spanner_sys.query_stats_top_minute 테이블로 사용하도록 수정된 이 쿼리는 Google Cloud 콘솔의 쿼리 페이지에서 쿼리 통계 쿼리 템플릿으로 … …
- Most searched keywords: Whether you are looking for 쿼리 통계 | Cloud Spanner | Google Cloud 참고 spanner_sys.query_stats_top_minute 테이블로 사용하도록 수정된 이 쿼리는 Google Cloud 콘솔의 쿼리 페이지에서 쿼리 통계 쿼리 템플릿으로 …
- Table of Contents:
가용성
쿼리별로 그룹화된 CPU 사용량
집계 통계
데이터 보관
쿼리 예
쿼리 통계로 CPU 사용량 또는 쿼리 지연 시간 증가 문제 해결
다음 단계
MY-SQL 각 테이블 일자별 통계쿼리
- Article author: velog.io
- Reviews from users: 23109 Ratings
- Top rated: 4.6
- Lowest rated: 1
- Summary of article content: Articles about MY-SQL 각 테이블 일자별 통계쿼리 본 글은 집계쿼리를 작성하는데 포커스가 맞춰져있으므로 테이블간의 세세한 관계는 간소화 하겠습니다. … MY-SQL 각 테이블 일자별 통계쿼리. …
- Most searched keywords: Whether you are looking for MY-SQL 각 테이블 일자별 통계쿼리 본 글은 집계쿼리를 작성하는데 포커스가 맞춰져있으므로 테이블간의 세세한 관계는 간소화 하겠습니다. … MY-SQL 각 테이블 일자별 통계쿼리. 서비스를 구축하다보면 일자별 통계를 구현할 상황이 있습니다. 가령 최근 한 주간의 가입된 회원, 작성된 글, 작성된 댓글의 수를 수치화 해야한다고 가정하겠습니다.본 글은 집계쿼리를 작성하는데 포커스가 맞춰져있으므로 테이블간의 세세한 관계는 간소화 하겠습니다. 집계쿼리를
- Table of Contents:
[Oracle/Sql] 통계테이블에 유용하게 쓰이는 pivot,rollup
- Article author: cpdev.tistory.com
- Reviews from users: 10658 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about [Oracle/Sql] 통계테이블에 유용하게 쓰이는 pivot,rollup front 작업만 해서 쿼리 만질일이 없다가 오랜만에 다시 쿼리를 해본다. 통계데이터를 만드는 일인데, 확실히 쿼리로 처리하면 java로 처리하는것 … …
- Most searched keywords: Whether you are looking for [Oracle/Sql] 통계테이블에 유용하게 쓰이는 pivot,rollup front 작업만 해서 쿼리 만질일이 없다가 오랜만에 다시 쿼리를 해본다. 통계데이터를 만드는 일인데, 확실히 쿼리로 처리하면 java로 처리하는것 … front 작업만 해서 쿼리 만질일이 없다가 오랜만에 다시 쿼리를 해본다. 통계데이터를 만드는 일인데, 확실히 쿼리로 처리하면 java로 처리하는것 보다 편하다. 1 2 3 4 5 6 7 8 9 with data as ( select ‘201..
- Table of Contents:
![[Oracle/Sql] 통계테이블에 유용하게 쓰이는 pivot,rollup](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F254D9446577D0DC601)
쿼리 íë¡íì ì¬ì©íì¬ ì¿¼ë¦¬ ë¶ìí기 — Snowflake Documentation
- Article author: docs.snowflake.com
- Reviews from users: 22299 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about 쿼리 íë¡íì ì¬ì©íì¬ ì¿¼ë¦¬ ë¶ìí기 — Snowflake Documentation 그리고 선택한 쿼리에 대해 전체 쿼리에 대한 세부 정보 및 통계와 함께 각 구성 요소에 대한 통계 및 쿼리 처리 계획의 주요 구성 요소를 그래픽으로 보여줍니다. …
- Most searched keywords: Whether you are looking for 쿼리 íë¡íì ì¬ì©íì¬ ì¿¼ë¦¬ ë¶ìí기 — Snowflake Documentation 그리고 선택한 쿼리에 대해 전체 쿼리에 대한 세부 정보 및 통계와 함께 각 구성 요소에 대한 통계 및 쿼리 처리 계획의 주요 구성 요소를 그래픽으로 보여줍니다.
- Table of Contents:
ìê°Â¶
쿼리 íë¡í ì¸í°íì´ì¤Â¶
ì°ì°ì íì ¶
쿼리ì°ì°ì ì¸ë¶ ì 보¶
쿼리 íë¡íì íµí´ íì¸ë ì¼ë° 쿼리 문ì ¶
[mysql] count 조건 설정하는 방법 [통계쿼리정리]
- Article author: chobopark.tistory.com
- Reviews from users: 22928 Ratings
- Top rated: 3.6
- Lowest rated: 1
- Summary of article content: Articles about [mysql] count 조건 설정하는 방법 [통계쿼리정리] 흔히들 통계에서 사용할 때 많이 사용되는 쿼리입니다. 제가 하고자하는 것은 Group by와 count를 통해 원하는 계산식을 얻을 예정인데,. …
- Most searched keywords: Whether you are looking for [mysql] count 조건 설정하는 방법 [통계쿼리정리] 흔히들 통계에서 사용할 때 많이 사용되는 쿼리입니다. 제가 하고자하는 것은 Group by와 count를 통해 원하는 계산식을 얻을 예정인데,. 안녕하세요 오늘은 count 조건 설정하는 방법에 대해 이야기해보겠습니다. 흔히들 통계에서 사용할 때 많이 사용되는 쿼리입니다. 제가 하고자하는 것은 Group by와 count를 통해 원하는 계산식을 얻을 예정인데,..
- Table of Contents:
1 count 안에서 조건설정
3 count 중복제거 조건 (distinct where)
4 from절 subquery 안에서 group by 설정
5 년월일 매칭 Count
6 날짜컬럼 년월일 구분 (group by)
7 날짜기간 Count
9 GROUP BY Count가 빈칸일 경우 0으로 표시하는 방법
10 기간만료 한달전 데이터 출력
태그
관련글
댓글0
공지사항
최근글
인기글
최근댓글
태그
전체 방문자
티스토리툴바
![[mysql] count 조건 설정하는 방법 [통계쿼리정리]](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F4P5mJ%2FbtqLlBVuy5m%2F9ixzFPUKsa06TGVUMsyTr0%2Fimg.png)
ëí íµê³ ë¡ê·¸ì ëí 쿼리 ì±ë¥ í¥ì
- Article author: www.ibm.com
- Reviews from users: 165 Ratings
- Top rated: 3.4
- Lowest rated: 1
- Summary of article content: Articles about ëí íµê³ ë¡ê·¸ì ëí 쿼리 ì±ë¥ í¥ì 통계 로그 파일이 대형인 경우, 로그 레코드를 테이블에 복사하고, 인덱스를 작성한 다음 통계를 수집하여 쿼리 성능을 향상시킬 수 있습니다. …
- Most searched keywords: Whether you are looking for ëí íµê³ ë¡ê·¸ì ëí 쿼리 ì±ë¥ í¥ì 통계 로그 파일이 대형인 경우, 로그 레코드를 테이블에 복사하고, 인덱스를 작성한 다음 통계를 수집하여 쿼리 성능을 향상시킬 수 있습니다. íµê³ ë¡ê·¸ íì¼ì´ ëíì¸ ê²½ì°, ë¡ê·¸ ë ì½ë를 í ì´ë¸ì ë³µì¬íê³ , ì¸ë±ì¤ë¥¼ ìì±í ë¤ì íµê³ë¥¼ ìì§íì¬ ì¿¼ë¦¬ ì±ë¥ì í¥ììí¬ ì ììµëë¤.ë¡ê·¸, íµê³
- Table of Contents:
íë¡ìì
ê´ë ¨ ê°ë
ê´ë ¨ 참조
See more articles in the same category here: 89+ tips for you.
힘차게, 열심히 공대생 :: [SQL] SQL 쿼리문, 통계 데이터 내기
1) Group by : 범주의 통계내기
select name, count(*) from users group by name;
group by name: name이라는 필드에서 동일한 값을 갖는 데이터를 하나로 합쳐줍니다
select name, count(*): 이름과 count(*)를 출력해 주는데, 여기서 count(*)는 group by로 합쳐진 데이터의 개수를 세어준다
2) Group by 기능 알아보기 (최소, 최대, 평균, 합계)
각각, min, max, avg, sum 키워드로 접근한다.
select 필드명, min(최솟값을 알고 싶은 필드명) from 테이블명 group by 범주가 담긴 필드명;
3) Order by : 정렬
실행결과를 정렬하고 싶을 때, orderby를 사용한다!
select name, count(*) from users group by name order by count(*);
👉 위 쿼리가 실행되는 순서: from → group by → select → order by
내림차순은 orderby 뒤에 desc를 붙혀준다
select name, count(*) from users group by name order by count(*) desc;
4) Orderby, Where절과 함께 짜기
[순서]orders 테이블에서 주문 데이터를 읽어오고 웹개발 종합반 데이터만 남기고 결제수단(범주) 별로 그룹화하고 결제수단별 주문건수를 세어준다!
select payment_method, count(*) from orders where course_title = “웹개발 종합반” group by payment_method order by count(*);
👉 order by는 맨 나중에 실행됩니다! (결과물을 정렬해주는 것이기 때문!)
728×90
반응형
Cloud Spanner
Cloud Spanner는 CPU를 가장 많이 사용하는 쿼리 및 DML 문과 모든 쿼리를 집계(변경 내역 쿼리 포함)하는 데 필요한 다양한 통계를 보관하는 테이블을 기본 제공합니다.
가용성
SPANNER_SYS 데이터는 SQL 인터페이스를 통해서만 사용할 수 있습니다. 예를 들면 다음과 같습니다.
Google Cloud 콘솔에 있는 데이터베이스의 쿼리 페이지
gcloud spanner databases execute-sql 명령어
executeQuery API
Cloud Spanner가 제공하는 다른 단일 읽기 메서드는 SPANNER_SYS 를 지원하지 않습니다.
참고: 데이터베이스 쿼리 페이지에서 이 페이지의 예시 쿼리를 복사 및 붙여넣거나 쿼리 템플릿 목록을 사용하여 쿼리를 신속하게 삽입할 수 있습니다.
쿼리별로 그룹화된 CPU 사용량
다음 테이블은 특정 기간 동안 CPU 사용량이 가장 높은 쿼리를 추적합니다.
SPANNER_SYS.QUERY_STATS_TOP_MINUTE : 1분 간격 동안의 쿼리
: 1분 간격 동안의 쿼리 SPANNER_SYS.QUERY_STATS_TOP_10MINUTE : 10분 간격 동안의 쿼리
: 10분 간격 동안의 쿼리 SPANNER_SYS.QUERY_STATS_TOP_HOUR : 1시간 간격 동안의 쿼리
이러한 테이블에는 다음과 같은 속성이 있습니다.
각 테이블에는 테이블 이름에 지정된 길이의 겹치지 않는 시간 간격에 대한 데이터가 포함되어 있습니다.
간격은 시계 시간을 기준으로 합니다. 1분 간격은 매분 정각에 끝나고, 10분 간격은 매시 정각에 시작해서 10분 단위로 끝나며, 1시간 간격은 매시 정각에 끝납니다. 예를 들어 오전 11:59:30에 SQL 쿼리에 사용할 수 있는 가장 최근 간격은 다음과 같습니다. 1분 : 오전 11:58:00–11:58:59 10분 : 오전 11:40:00–11:49:59 1시간 : 오전 10:00:00~10:59:59
Cloud Spanner는 SQL 쿼리의 텍스트를 기준으로 통계를 그룹화합니다. 쿼리에 쿼리 매개변수가 사용된 경우 Cloud Spanner는 해당 쿼리의 모든 실행을 하나의 행으로 그룹화합니다. 쿼리에 문자열 리터럴이 사용된 경우 Cloud Spanner는 전체 쿼리 텍스트가 동일할 때만 통계를 그룹화하므로 다른 텍스트가 있으면 각 쿼리가 개별 행으로 표시됩니다. 일괄 DML의 경우 Cloud Spanner는 디지털 지문을 생성하기 전에 연속된 동일한 문을 중복 처리하여 배치를 정규화합니다.
각 행에는 Cloud Spanner가 지정된 간격 동안 통계를 캡처하는 특정 SQL 쿼리의 모든 실행에 대한 통계가 포함됩니다.
Cloud Spanner가 특정 간격 동안 실행된 모든 쿼리를 저장할 수 없는 경우에는 지정된 간격 동안 CPU 사용량이 가장 높은 쿼리부터 우선적으로 저장됩니다.
추적된 쿼리에는 사용자가 완료, 실패 또는 취소한 쿼리가 포함됩니다.
통계의 하위 집합은 실행되었지만 완료되지 않은 쿼리에 따라 다릅니다. 실패한 모든 쿼리의 실행 수와 평균 지연 시간(초 단위)입니다. 타임아웃된 쿼리의 실행 수입니다. 사용자가 취소했거나 네트워크 연결 문제로 인해 실패한 쿼리의 실행 수입니다.
테이블 스키마
열 이름 유형 설명 INTERVAL_END TIMESTAMP 포함된 쿼리 실행이 발생한 시간 간격의 끝입니다. REQUEST_TAG STRING 이 쿼리 작업의 선택적 요청 태그입니다. 태그 사용에 대한 자세한 내용은 요청 태그 문제 해결을 참조하세요. TEXT STRING SQL 쿼리 텍스트로, 약 64KB 크기로 잘립니다.
태그 문자열이 동일한 여러 쿼리의 통계는 해당 태그 문자열과 일치하는 REQUEST_TAG 와 함께 단일 행으로 그룹화됩니다. 이러한 쿼리 중 하나의 텍스트만 약 64KB 크기로 잘린 상태로 이 필드에 표시됩니다. 일괄 DML의 경우 SQL 문 집합이 세미콜론을 사용해 연결된 단일 행으로 평면화됩니다. 연속된 동일한 SQL 텍스트는 자르기 전에 중복 삭제됩니다. TEXT_TRUNCATED BOOL 쿼리 텍스트가 잘렸는지 여부입니다. TEXT_FINGERPRINT INT64 REQUEST_TAG 값의 해시가 있는 경우입니다. 그렇지 않으면 TEXT 값의 해시입니다. EXECUTION_COUNT INT64 해당 간격 동안 Cloud Spanner가 쿼리를 캡처한 횟수입니다. AVG_LATENCY_SECONDS FLOAT64 데이터베이스 내 각 쿼리 실행의 평균 시간(초)입니다. 이 평균에서 결과 집합의 인코딩 및 전송 시간과 오버헤드는 제외됩니다. AVG_ROWS FLOAT64 쿼리가 반환한 평균 행 수입니다. AVG_BYTES FLOAT64 쿼리에서 반환된 평균 데이터 바이트 수입니다(전송 인코딩 오버헤드 제외). AVG_ROWS_SCANNED FLOAT64 쿼리에서 스캔된 평균 행 수입니다(삭제된 값 제외). AVG_CPU_SECONDS FLOAT64 Cloud Spanner가 쿼리를 실행하기 위해 모든 작업에 소비한 평균 CPU 시간(초)입니다. ALL_FAILED_EXECUTION_COUNT INT64 간격 중에 쿼리가 실패한 횟수입니다. ALL_FAILED_AVG_LATENCY_SECONDS FLOAT64 데이터베이스 내 실패한 각 쿼리 실행의 평균 시간(초)입니다. 이 평균에서 결과 집합의 인코딩 및 전송 시간과 오버헤드는 제외됩니다. CANCELLED_OR_DISCONNECTED_EXECUTION_COUNT INT64 사용자가 쿼리를 취소했거나 간격 중에 네트워크 연결이 끊어져 쿼리가 취소된 횟수입니다. TIMED_OUT_EXECUTION_COUNT INT64 간격 중에 쿼리가 타임아웃된 횟수입니다. AVG_BYTES_WRITTEN FLOAT64 문으로 작성된 평균 바이트 수입니다. AVG_ROWS_WRITTEN FLOAT64 문으로 수정된 평균 행 수입니다. STATEMENT_COUNT INT64 이 항목에 집계된 문의 합계입니다. 일반 쿼리 및 DML의 경우 실행 횟수와 동일합니다. 일괄 DML의 경우 Cloud Spanner는 배치의 문 수를 캡처합니다.
실패한 쿼리의 EXECUTION_COUNT 및 AVG_LATENCY_SECONDS 에는 잘못된 구문으로 인해 실패했거나 일시적인 오류가 발생하지만 재시도에 성공한 쿼리가 포함됩니다.
집계 통계
특정 기간 동안 Cloud Spanner가 통계를 캡처한 모든 쿼리에 대한 집계 데이터를 추적하는 테이블도 있습니다.
SPANNER_SYS.QUERY_STATS_TOTAL_MINUTE : 1분 간격 동안의 쿼리
: 1분 간격 동안의 쿼리 SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE : 10분 간격 동안의 쿼리
: 10분 간격 동안의 쿼리 SPANNER_SYS.QUERY_STATS_TOTAL_HOUR : 1시간 간격 동안의 쿼리
이러한 테이블에는 다음과 같은 속성이 있습니다.
각 테이블에는 테이블 이름에 지정된 길이의 겹치지 않는 시간 간격에 대한 데이터가 포함되어 있습니다.
간격은 시계 시간을 기준으로 합니다. 1분 간격은 매분 정각에 끝나고, 10분 간격은 매시 정각에 시작해서 10분 단위로 끝나며, 1시간 간격은 매시 정각에 끝납니다. 예를 들어 오전 11:59:30에 SQL 쿼리에 사용할 수 있는 가장 최근 간격은 다음과 같습니다. 1분 : 오전 11:58:00–11:58:59 10분 : 오전 11:40:00–11:49:59 1시간 : 오전 10:00:00~10:59:59
각 행에는 지정된 간격 동안 데이터베이스에 대해 실행된 모든 쿼리에 대한 통계가 함께 집계됩니다. 시간 간격당 하나의 행만 있으며 완료된 쿼리, 실패한 쿼리, 사용자가 취소한 쿼리가 포함됩니다.
TOTAL 테이블에 캡처되는 통계에는 Cloud Spanner가 TOP 테이블에 캡처하지 않은 쿼리도 포함될 수 있습니다.
이러한 테이블의 일부 열은 Cloud Monitoring에서 측정항목으로 노출됩니다. 노출된 측정항목은 다음과 같습니다. 쿼리 실행 횟수 쿼리 실패 쿼리 지연 시간 반환된 행 수 스캔된 행 수 반환된 바이트 수 쿼리 CPU 시간 자세한 내용은 Cloud Spanner 측정항목을 참조하세요.
테이블 스키마
열 이름 유형 설명 INTERVAL_END TIMESTAMP 포함된 쿼리 실행이 발생한 시간 간격의 끝입니다. EXECUTION_COUNT INT64 일정 기간 동안 Cloud Spanner에서 쿼리를 본 횟수입니다. AVG_LATENCY_SECONDS FLOAT64 데이터베이스 내 각 쿼리 실행의 평균 시간(초)입니다. 이 평균에서 결과 집합의 인코딩 및 전송 시간과 오버헤드는 제외됩니다. AVG_ROWS FLOAT64 쿼리가 반환한 평균 행 수입니다. AVG_BYTES FLOAT64 쿼리에서 반환된 평균 데이터 바이트 수입니다(전송 인코딩 오버헤드 제외). AVG_ROWS_SCANNED FLOAT64 쿼리에서 스캔된 평균 행 수입니다(삭제된 값 제외). AVG_CPU_SECONDS FLOAT64 Cloud Spanner가 쿼리를 실행하기 위해 모든 작업에 소비한 평균 CPU 시간(초)입니다. ALL_FAILED_EXECUTION_COUNT INT64 간격 중에 쿼리가 실패한 횟수입니다. ALL_FAILED_AVG_LATENCY_SECONDS FLOAT64 데이터베이스 내 실패한 각 쿼리 실행의 평균 시간(초)입니다. 이 평균에서 결과 집합의 인코딩 및 전송 시간과 오버헤드는 제외됩니다. CANCELLED_OR_DISCONNECTED_EXECUTION_COUNT INT64 사용자가 쿼리를 취소했거나 간격 중에 네트워크 연결이 끊어져 쿼리가 취소된 횟수입니다. TIMED_OUT_EXECUTION_COUNT INT64 간격 중에 쿼리가 타임아웃된 횟수입니다. AVG_BYTES_WRITTEN FLOAT64 문으로 작성된 평균 바이트 수입니다. AVG_ROWS_WRITTEN FLOAT64 문으로 수정된 평균 행 수입니다.
데이터 보관
Cloud Spanner는 각 테이블의 데이터를 최소한 다음 기간 동안 보관합니다.
SPANNER_SYS.QUERY_STATS_TOP_MINUTE 및 SPANNER_SYS.QUERY_STATS_TOTAL_MINUTE : 이전 6시간을 포함하는 간격
SPANNER_SYS.QUERY_STATS_TOP_10MINUTE 및 SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE : 이전 4일을 포함하는 간격
SPANNER_SYS.QUERY_STATS_TOP_HOUR 및 SPANNER_SYS.QUERY_STATS_TOTAL_HOUR : 이전 30일을 포함하는 간격
참고: Cloud Spanner의 쿼리 통계 수집을 중지할 수 없습니다. 이러한 테이블의 데이터를 삭제하려면 테이블과 연결된 데이터베이스를 삭제하거나 Cloud Spanner가 자동으로 데이터를 삭제할 때까지 기다려야 합니다.
쿼리 예
이 섹션에는 쿼리 통계를 검색하는 SQL 문의 몇 가지 예가 포함되어 있습니다. 이러한 SQL 문은 클라이언트 라이브러리, gcloud 명령줄 도구 또는 Google Cloud 콘솔을 사용하여 실행할 수 있습니다.
일정 기간 동안 각 쿼리의 기본 통계 나열
다음 쿼리는 이전 1분 동안의 상위 쿼리에 대한 원시 데이터를 반환합니다.
SELECT text, request_tag, interval_end, execution_count, avg_latency_seconds, avg_rows, avg_bytes, avg_rows_scanned, avg_cpu_seconds FROM spanner_sys.query_stats_top_minute ORDER BY interval_end DESC;
CPU 사용량이 가장 높은 쿼리 나열
다음 쿼리는 이전 1시간 동안 CPU 사용량이 가장 높은 쿼리를 반환합니다.
SELECT text, request_tag, execution_count AS count, avg_latency_seconds AS latency, avg_cpu_seconds AS cpu, execution_count * avg_cpu_seconds AS total_cpu FROM spanner_sys.query_stats_top_hour WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_top_hour) ORDER BY total_cpu DESC;
참고 spanner_sys.query_stats_top_minute 테이블로 사용하도록 수정된 이 쿼리는 Google Cloud 콘솔의 쿼리 페이지에서 쿼리 통계 쿼리 템플릿으로 사용할 수 있습니다.
일정 기간 동안의 총 실행 횟수 확인
다음 쿼리는 가장 최근의 1분 간격 동안 실행된 쿼리의 총 수를 반환합니다.
SELECT interval_end, execution_count FROM spanner_sys.query_stats_total_minute WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_top_minute);
쿼리의 평균 지연 시간 확인
다음 쿼리는 특정 쿼리의 평균 지연 시간 정보를 반환합니다.
SELECT avg_latency_seconds FROM spanner_sys.query_stats_top_hour WHERE text LIKE “SELECT x FROM table WHERE x=@foo;”;
가장 많은 데이터를 검색한 쿼리 확인
쿼리에서 스캔된 행의 개수를 사용하여 쿼리에서 스캔된 데이터의 양을 측정할 수 있습니다. 다음 쿼리는 이전 1시간 동안 실행된 쿼리에서 스캔된 행의 개수를 반환합니다.
SELECT text, execution_count, avg_rows_scanned FROM spanner_sys.query_stats_top_hour WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_top_hour) ORDER BY avg_rows_scanned DESC;
가장 많은 데이터를 작성한 문 확인
DML이 작성한 행 또는 바이트 수를 사용하면 쿼리가 수정한 데이터의 양을 측정할 수 있습니다. 다음 쿼리는 이전 1시간 동안 실행된 DML 문이 작성한 행 수를 반환합니다.
SELECT text, execution_count, avg_rows_written FROM spanner_sys.query_stats_top_hour WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_top_hour) ORDER BY avg_rows_written DESC;
모든 쿼리의 CPU 사용량 합계 확인
다음 쿼리는 이전 1시간 동안 사용된 CPU 시간 수를 반환합니다.
SELECT (avg_cpu_seconds * execution_count / 60 / 60) AS total_cpu_hours FROM spanner_sys.query_stats_total_hour WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_total_hour);
특정 기간 동안 실패한 쿼리 나열
다음 쿼리는 이전 1분 동안의 상위 쿼리에 대한 실행 횟수 및 실패한 쿼리의 평균 지연 시간을 포함한 원시 데이터를 반환합니다.
SELECT text, request_tag, interval_end, execution_count, all_failed_execution_count, all_failed_avg_latency_seconds, avg_latency_seconds, avg_rows, avg_bytes, avg_rows_scanned, avg_cpu_seconds FROM spanner_sys.query_stats_top_minute WHERE all_failed_execution_count > 0 ORDER BY interval_end;
특정 기간 동안의 총 오류 수 확인
다음 쿼리는 가장 최근의 1분 간격에서 실행할 수 없었던 총 쿼리 수를 반환합니다.
SELECT interval_end, all_failed_execution_count FROM spanner_sys.query_stats_total_minute WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_top_minute) ORDER BY interval_end;
가장 많이 시간 초과된 쿼리 나열
다음 쿼리는 이전 1시간 안에 시간 초과 횟수가 가장 많은 쿼리를 반환합니다.
SELECT text, execution_count AS count, timed_out_execution_count AS timeout_count, avg_latency_seconds AS latency, avg_cpu_seconds AS cpu, execution_count * avg_cpu_seconds AS total_cpu FROM spanner_sys.query_stats_top_hour WHERE interval_end = (SELECT MAX(interval_end) FROM spanner_sys.query_stats_top_hour) ORDER BY timed_out_execution_count DESC;
성공 및 실패한 쿼리 실행의 평균 지연 시간 확인
다음 쿼리는 특정 쿼리의 평균 실행 지연 시간 조합, 성공한 실행의 평균 지연 시간, 실패한 실행의 평균 지연 시간을 반환합니다.
SELECT avg_latency_seconds AS combined_avg_latency, all_failed_avg_latency_seconds AS failed_execution_latency, ( avg_latency_seconds * execution_count – all_failed_avg_latency_seconds * all_failed_execution_count ) / ( execution_count – all_failed_execution_count ) AS success_execution_latency FROM spanner_sys.query_stats_top_hour WHERE text LIKE “select x from table where x=@foo;”;
쿼리 통계로 CPU 사용량 또는 쿼리 지연 시간 증가 문제 해결
쿼리 통계는 Cloud Spanner 데이터베이스에서 높은 CPU 사용량을 조사해야 하거나 데이터베이스에서 CPU 사용량이 많은 쿼리 형태를 파악하려는 경우에 유용합니다. Cloud Spanner 사용자는 상당한 양의 데이터베이스 리소스를 사용하는 쿼리를 검사하여 운영 비용을 줄이고 일반적인 시스템 지연 시간을 개선할 수 있습니다. 다음 단계에서는 쿼리 통계를 사용하여 데이터베이스의 높은 CPU 사용량을 조사하는 방법을 보여줍니다.
아래 예시에서는 CPU 사용량에 중점을 두고 있지만 유사한 단계를 수행하여 높은 쿼리 지연 시간 문제를 해결하고 지연 시간이 가장 긴 쿼리를 찾을 수 있습니다. CPU 사용량 대신 지연 시간으로 시간 간격 및 쿼리를 선택하면 됩니다.
조사할 기간 선택
애플리케이션에서 CPU 사용량이 많을 때를 찾아 조사를 시작합니다. 예를 들어 2020년 7월 24일 오후 5시(UTC)에 문제가 발생하기 시작했다고 가정해 보겠습니다.
선택한 기간의 쿼리 통계 수집
조사를 시작하는 기간을 선택했으므로 해당 시간 동안의 QUERY_STATS_TOTAL_10MINUTE 테이블에서 수집된 통계를 살펴봅니다. 이 쿼리 결과를 통해 해당 기간 동안 CPU 및 기타 쿼리 통계가 어떻게 변경되었는지 알 수 있습니다.
다음 쿼리는 포괄적으로 16:30부터 17:30 UTC까지 집계된 쿼리 통계를 반환합니다. 쿼리에서 ROUND 를 사용하여 표시 목적으로 소수점 자릿수를 제한합니다.
SELECT interval_end, execution_count AS count, ROUND(avg_latency_seconds,2) AS latency, ROUND(avg_rows,2) AS rows_returned, ROUND(avg_bytes,2) AS bytes, ROUND(avg_rows_scanned,2) AS rows_scanned, ROUND(avg_cpu_seconds,3) AS avg_cpu FROM spanner_sys.query_stats_total_10minute WHERE interval_end >= “2020-07-24T16:30:00Z” AND interval_end <= "2020-07-24T17:30:00Z" ORDER BY interval_end; 쿼리를 실행하여 다음과 같은 결과가 생성되었습니다. interval_end 수 지연 시간 rows_returned 바이트 rows_scanned avg_cpu 2020-07-24T16:30:00Z 6 0.06 5.00 536.00 16.67 0.035 2020-07-24T16:40:00Z 55 0.02 0.22 25.29 0.22 0.004 2020-07-24T16:50:00Z 102 0.02 0.30 33.35 0.30 0.004 2020-07-24T17:00:00Z 154 1.06 4.42 486.33 7792208.12 4.633 2020-07-24T17:10:00Z 94 0.02 1.68 106.84 1.68 0.006 2020-07-24T17:20:00Z 110 0.02 0.38 34.60 0.38 0.005 2020-07-24T17:30:00Z 47 0.02 0.23 24.96 0.23 0.004 위 표에서 결과 테이블에 있는 avg_cpu 열이 나타내는 평균 CPU 시간은 17:00로 끝나는 강조표시된 구간에서 가장 높게 나타납니다. 또한 평균적으로 스캔된 행의 수가 훨씬 더 많음을 알 수 있습니다. 이는 더 많은 고비용 쿼리가 16:50에서 17:00 사이에 실행되었음을 나타냅니다. 다음 단계에서 해당 간격을 더 자세히 조사해 보겠습니다. 높은 CPU 사용량을 유발하는 쿼리 확인 조사하기 위해 선택한 시간 간격으로 이제 QUERY_STATS_TOP_10MINUTE 테이블을 쿼리합니다. 이 쿼리의 결과를 통해 높은 CPU 사용량을 유발하는 쿼리를 파악할 수 있습니다. SELECT text_fingerprint AS fingerprint, execution_count AS count, ROUND(avg_latency_seconds,2) AS latency, ROUND(avg_cpu_seconds,3) AS cpu, ROUND(execution_count * avg_cpu_seconds,3) AS total_cpu FROM spanner_sys.query_stats_top_10MINUTE WHERE interval_end = "2020-07-24T17:00:00Z" ORDER BY total_cpu DESC; 이 쿼리를 실행하면 다음과 같은 결과가 표시됩니다. 디지털 지문 수 지연 시간 CPU total_cpu 5505124206529314852 30 3.88 17.635 529.039 1697951036096498470 10 4.49 18.388 183.882 2295109096748351518 1 0.33 0.048 0.048 11618299167612903606 1 0.25 0.021 0.021 10302798842433860499 1 0.04 0.006 0.006 123771704548746223 1 0.04 0.006 0.006 4216063638051261350 1 0.04 0.006 0.006 3654744714919476398 1 0.04 0.006 0.006 2999453161628434990 1 0.04 0.006 0.006 823179738756093706 1 0.02 0.005 0.0056 결과 테이블에 강조 표시된 상위 2개 쿼리는 평균 CPU 및 지연 시간과 실행 횟수 및 총 실행 횟수의 측면에서 이상점입니다. 이러한 결과에 나열된 첫 번째 쿼리를 조사해 보겠습니다. 시간 경과에 따른 쿼리 실행 비교 조사 범위를 좁힘으로써 QUERY_STATS_TOP_MINUTE 테이블에 주목할 수 있습니다. 시간 경과에 따라 특정 쿼리의 실행을 비교하여, 반환된 행 또는 바이트 수, 또는 스캔된 행과 증가한 CPU 사용량 또는 지연시간 간의 상관관계를 찾을 수 있습니다. 편차는 데이터가 일관성이 없음을 나타낼 수 있습니다. 지속적으로 스캔된 행 수가 많으면 적절한 색인이 부족하거나 최적화되지 않은 조인 순서 지정이 원인일 수 있습니다. 해당 쿼리의 text_fingerprint를 필터링하는 다음 문을 실행하여 평균 CPU 사용량이 가장 높고 지연 시간이 가장 긴 쿼리를 조사해 보겠습니다. SELECT interval_end, ROUND(avg_latency_seconds,2) AS latency, avg_rows AS rows_returned, avg_bytes AS bytes_returned, avg_rows_scanned AS rows_scanned, ROUND(avg_cpu_seconds,3) AS cpu, FROM spanner_sys.query_stats_top_minute WHERE text_fingerprint = 5505124206529314852 ORDER BY interval_end DESC; 이 쿼리를 실행하면 다음과 같은 결과가 반환됩니다. interval_end 지연 시간 rows_returned bytes_returned rows_scanned CPU 2020-07-24T17:00:00Z 4.55 21 2365 30000000 19.255 2020-07-24T16:00:00Z 3.62 21 2365 30000000 17.255 2020-07-24T15:00:00Z 4.37 21 2365 30000000 18.350 2020-07-24T14:00:00Z 4.02 21 2365 30000000 17.748 2020-07-24T13:00:00Z 3.12 21 2365 30000000 16.380 2020-07-24T12:00:00Z 3.45 21 2365 30000000 15.476 2020-07-24T11:00:00Z 4.94 21 2365 30000000 22.611 2020-07-24T10:00:00Z 6.48 21 2365 30000000 21.265 2020-07-24T09:00:00Z 0.23 21 2365 5 0.040 2020-07-24T08:00:00Z 0.04 21 2365 5 0.021 2020-07-24T07:00:00Z 0.09 21 2365 5 0.030 위 결과를 검사한 결과 스캔된 행의 개수, 사용된 CPU, 지연 시간이 약 오전 9시 무렵에 크게 변했습니다. 이러한 숫자가 크게 증가한 이유를 이해할 수 있도록 쿼리 텍스트를 검사하여 스키마 변경이 쿼리에 영향을 미쳤는지 여부를 살펴보겠습니다. 다음 쿼리를 사용하여 조사 중인 쿼리의 쿼리 텍스트를 검색합니다. SELECT text, text_truncated FROM spanner_sys.query_stats_top_hour WHERE text_fingerprint = 5505124206529314852 LIMIT 1; 그러면 다음 결과가 반환됩니다. text text_truncated select * from orders where o_custkey = 36901; false 반환된 쿼리 텍스트를 살펴보면 쿼리가 o_custkey 라는 필드에서 필터링된다는 것을 알 수 있습니다. 이 필드는 orders 테이블의 키 열이 아닌 열입니다. 필터링되면서 오전 9시 무렵에 삭제된 열에 대한 색인을 볼 수 있었습니다. 이 색인은 이 쿼리의 비용 변동을 설명합니다. 색인을 다시 추가하거나, 쿼리가 자주 실행되지 않는 경우 색인을 사용하지 않고 더 높은 읽기 비용을 수용할 수 있습니다. 성공적으로 완료된 쿼리에 중점을 둔 지금까지의 조사 결과, 데이터베이스에 성능 저하가 발생한 한 가지 이유를 찾게 되었습니다. 다음 단계에서는 실패 또는 취소된 쿼리에 중점을 두고 더 많은 유용한 정보를 위해 해당 데이터를 검사하는 방법을 설명합니다. 실패한 쿼리 조사 성공적으로 완료되지 않은 쿼리는 시간 초과, 취소 또는 실패하기 전까지 리소스를 계속 사용합니다. Cloud Spanner는 성공한 쿼리와 함께 실패한 쿼리에 의해 소비된 실행 횟수 및 리소스를 추적합니다. 실패한 쿼리가 시스템 사용률에 현저한 영향을 주는지 확인하려면 먼저 관심 있는 시간 간격에서 실패한 쿼리 수를 확인합니다. SELECT interval_end, all_failed_execution_count AS failed_count, all_failed_avg_latency_seconds AS latency FROM spanner_sys.query_stats_total_minute WHERE interval_end >= “2020-07-24T16:50:00Z” AND interval_end <= "2020-07-24T17:00:00Z" ORDER BY interval_end; interval_end failed_count 지연 시간 2020-07-24T16:52:00Z 1 15.211391 2020-07-24T16:53:00Z 3 58.312232 추가로 조사하여 다음 쿼리를 통해 실패할 가능성이 가장 높은 쿼리를 찾을 수 있습니다. SELECT interval_end, text_fingerprint, execution_count, avg_latency_seconds AS avg_latency, all_failed_execution_count AS failed_count, all_failed_avg_latency_seconds AS failed_latency, cancelled_or_disconnected_execution_count AS cancel_count, timed_out_execution_count AS to_count FROM spanner_sys.query_stats_top_minute WHERE all_failed_execution_count > 0 ORDER BY interval_end;
interval_end text_fingerprint execution_count failed_count cancel_count to_count 2020-07-24T16:52:00Z 5505124206529314852 3 1 1 0 2020-07-24T16:53:00Z 1697951036096498470 2 1 1 0 2020-07-24T16:53:00Z 5505124206529314852 5 2 1 1
위 표에 나타난 것처럼 디지털 지문이 5505124206529314852 인 쿼리는 서로 다른 시간 간격 동안 여러 번 실패했습니다. 이와 같은 실패 패턴을 미루어 보아 성공한 실행과 실패한 실행의 지연 시간 비교는 주목할 만합니다.
SELECT interval_end, avg_latency_seconds AS combined_avg_latency, all_failed_avg_latency_seconds AS failed_execution_latency, ( avg_latency_seconds * execution_count – all_failed_avg_latency_seconds * all_failed_execution_count ) / ( execution_count – all_failed_execution_count ) AS success_execution_latency FROM spanner_sys.query_stats_top_hour WHERE text_fingerprint = 5505124206529314852;
interval_end combined_avg_latency failed_execution_latency success_execution_latency 2020-07-24T17:00:00Z 3.880420 13.830709 2.774832
권장사항 적용
최적화를 위해 후보 쿼리를 식별하면, 그 다음엔 쿼리 프로필을 살펴본 후 SQL 권장사항을 사용하여 최적화를 수행할 수 있습니다.
다음 단계
MY-SQL 각 테이블 일자별 통계쿼리
배경
서비스를 구축하다보면 일자별 통계를 구현할 상황이 있습니다. 가령 최근 한 주간의 가입된 회원, 작성된 글, 작성된 댓글의 수를 수치화 해야한다고 가정하겠습니다.
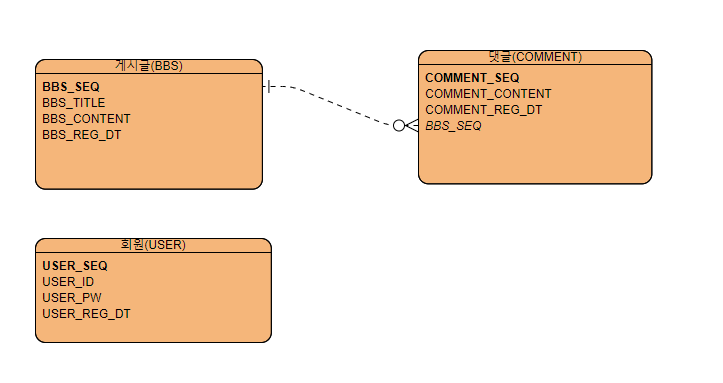
TABLE
본 글은 집계쿼리를 작성하는데 포커스가 맞춰져있으므로 테이블간의 세세한 관계는 간소화 하겠습니다. 집계쿼리를 작성할 때 테이블이 3개이상일 확률이 크나 해결방법은 같습니다.
현황
각 테이블의 1주일간 데이터 (2021.06.16 ~ 2021.06.22)
게시글BBS의 1주일간 데이터 조회 (3건)
SELECT TITLE ,CONTENT , DATE_FORMAT(REG_DT, “%Y-%m-%d”) AS REG_DT FROM BBS WHERE REG_DT BETWEEN DATE_FORMAT(DATE_SUB(NOW(), INTERVAL 7 DAY ), “%Y-%m-%d”) AND now();
게시글에대한 댓글COMMENT의 1주일간 데이터 조회 (6건)
SELECT BBS_COMMENT ,REG_NAME , DATE_FORMAT(REG_DT, “%Y-%m-%d”) AS REG_DT FROM `COMMENT` WHERE REG_DT BETWEEN DATE_FORMAT(DATE_SUB(NOW(), INTERVAL 7 DAY ), “%Y-%m-%d”) AND NOW();
회원가입에 대한 1주일간의 데이터 조회 (1건)
SELECT USER_ID ,DATE_FORMAT(REG_DT, “%Y-%m-%d”) AS REG_DT FROM `USER` WHERE REG_DT BETWEEN DATE_FORMAT(DATE_SUB(NOW(), INTERVAL 7 DAY ), “%Y-%m-%d”) AND NOW();
Idea
1) 서비스는 최근 1주일 (2021.06.16 ~ 2021.06.22) 간 댓글을 작성되지 않은날, 게시글이 작성되지 않은날, 가입자가 존재하지 않는날도 존재하므로 1주간의 날짜를 가지는 임의의 durmmy table이 필요하므로 가상의 table을 조회하는 작업을 실시한다.
SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 0 DAY), “%Y-%m-%d”) AS DT UNION ALL SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 1 DAY), “%Y-%m-%d”) UNION ALL SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 2 DAY), “%Y-%m-%d”) UNION ALL SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 3 DAY), “%Y-%m-%d”) UNION ALL SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 4 DAY), “%Y-%m-%d”) UNION ALL SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 5 DAY), “%Y-%m-%d”) UNION ALL SELECT DATE_FORMAT(DATE_SUB(now(), INTERVAL 6 DAY), “%Y-%m-%d”)
2) USER, COMMENT, BBS에서 기간별 각 각의 날짜의 투플의 수를 더한 테이블을 조회한다.
이 때 가입은 JN, 댓글은 CM, 글 작성에는 BD 라는 문자열로 라벨링을 한다.
SELECT DATE_FORMAT(REG_DT, “%Y-%m-%d”) AS DT ,COUNT(*) AS CNT , ‘JN’ AS GRB FROM `USER` GROUP BY DT UNION ALL SELECT DATE_FORMAT(REG_DT, “%Y-%m-%d”) AS DT ,COUNT(*) AS CNT ,’BD’ AS GRB FROM BBS GROUP BY DT UNION ALL SELECT DATE_FORMAT(REG_DT, ‘%Y-%m-%d’) AS DT ,COUNT(*) AS CNT ,’CM’ AS GRB FROM `COMMENT` GROUP BY DT
3) 1번 table에 LEFT OUTTER JOIN 을 통해 2번 table을 JOIN -> 최근 1주간의 날짜별 정렬
-> 2번 table에 라벨링한 데이터를 CASE WHEN THEN ELSE END 구문을 통해 카운팅 한다.
SELECT CRT_DT . DT , SUM ( CASE WHEN ORN_DT . GRB = ‘JN’ THEN ORN_DT . CNT ELSE 0 END ) AS JN_CNT , SUM ( CASE WHEN ORN_DT . GRB = ‘BD’ THEN ORN_DT . CNT ELSE 0 END ) AS BD_CNT , SUM ( CASE WHEN ORN_DT . GRB = ‘CM’ THEN ORN_DT . CNT ELSE 0 END ) AS CM_CNT FROM ( SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 0 DAY ) , “%Y-%m-%d” ) AS DT UNION ALL SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 1 DAY ) , “%Y-%m-%d” ) UNION ALL SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 2 DAY ) , “%Y-%m-%d” ) UNION ALL SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 3 DAY ) , “%Y-%m-%d” ) UNION ALL SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 4 DAY ) , “%Y-%m-%d” ) UNION ALL SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 5 DAY ) , “%Y-%m-%d” ) UNION ALL SELECT DATE_FORMAT ( DATE_SUB ( now ( ) , INTERVAL 6 DAY ) , “%Y-%m-%d” ) ) AS CRT_DT LEFT OUTER JOIN ( SELECT DATE_FORMAT ( REG_DT , “%Y-%m-%d” ) AS DT , COUNT ( * ) AS CNT , ‘JN’ AS GRB FROM ` USER ` GROUP BY DT UNION ALL SELECT DATE_FORMAT ( REG_DT , “%Y-%m-%d” ) AS DT , COUNT ( * ) AS CNT , ‘BD’ AS GRB FROM BBS GROUP BY DT UNION ALL SELECT DATE_FORMAT ( REG_DT , ‘%Y-%m-%d’ ) AS DT , COUNT ( * ) AS CNT , ‘CM’ AS GRB FROM ` COMMENT ` GROUP BY DT ) AS ORN_DT ON CRT_DT . DT = ORN_DT . DT GROUP BY CRT_DT . DT
마치며
이러한 통계쿼리를 통해 google chart나 여러 오픈소스의 grid등 통해 시각화 할 수 있습니다.
So you have finished reading the 통계 쿼리 topic article, if you find this article useful, please share it. Thank you very much. See more: 통계 쿼리 예제, Oracle 통계 쿼리, MySQL 통계쿼리, SQL 통계 쿼리, 오라클 통계 쿼리 예제, 통계 SQL, 일자별 통계 쿼리, 오라클 월별 통계 쿼리