
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 로그 변환 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://toplist.maxfit.vn team, along with other related topics such as: 로그 변환 로그 변환 계산기, 로그변환 이유, 로그변환 r, 로그 밑변환, 머신러닝 로그 변환, 로그 지수 변환, 자연로그 변환, 시계열로그 변환
로그의 밑 변환 공식은 원래 있던 로그의 밑을 새로운 밑으로 바꿀 때 원래 로그의 모양이 어떻게 바뀌는지를 공식으로 나타낸 거예요. ax = b를 로그로 변환해보죠. ax = b의 양변을 c(c > 0, c ≠ 1)을 밑으로 하는 로그를 취해보죠.
로그의 밑 변환 공식 – 수학방
- Article author: mathbang.net
- Reviews from users: 17508
 Ratings
Ratings - Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about 로그의 밑 변환 공식 – 수학방 Updating …
- Most searched keywords: Whether you are looking for 로그의 밑 변환 공식 – 수학방 Updating 로그의 밑 변환 공식이에요. 로그에서 밑은 log 옆에 작게 쓰는 걸 말하죠? 이걸 변환시킬 수 있는 공식이에요. 이름 그대로 공식이니까 외워야겠죠? 이 로그의 밑 변환 공식을 알고 있어야 다음에 공부할 로그의..
- Table of Contents:
로그의 밑 변환 공식
댓글(16개) 펼치기닫기

[회귀분석] 로그 변환 (Log transformation)은 언제, 어떻게 쓰는가? : 네이버 블로그
- Article author: m.blog.naver.com
- Reviews from users: 45405 Ratings
- Top rated: 4.5
- Lowest rated: 1
- Summary of article content: Articles about [회귀분석] 로그 변환 (Log transformation)은 언제, 어떻게 쓰는가? : 네이버 블로그 앞서 로그 변환에 대해서 다루어 보았는데, 변수의 변환이 새로운 입력과 출력 사이의 관계를 야기시킨다는 것은 명백해졌다. …
- Most searched keywords: Whether you are looking for [회귀분석] 로그 변환 (Log transformation)은 언제, 어떻게 쓰는가? : 네이버 블로그 앞서 로그 변환에 대해서 다루어 보았는데, 변수의 변환이 새로운 입력과 출력 사이의 관계를 야기시킨다는 것은 명백해졌다.
- Table of Contents:
카테고리 이동
자연의 원리에 귀를 기울이다
이 블로그
회귀(Regression)
카테고리 글
카테고리
이 블로그
회귀(Regression)
카테고리 글
![[회귀분석] 로그 변환 (Log transformation)은 언제, 어떻게 쓰는가? : 네이버 블로그](https://blogthumb.pstatic.net/MjAxODAxMTJfMjEx/MDAxNTE1NzI3MzI4MTg5.k5nFBhryIQFPwkrIfUqlOhDXy8tBJEumF4hbG4fy9log.CWADBArF4XBH2v465KswmtuQn9ITptPAumXMUUq2L1Ag.PNG.sw4r/image.png?type=w2)
[수2 이론] 로그 기본성질과 밑변환 :: winner
- Article author: j1w2k3.tistory.com
- Reviews from users: 37031 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about [수2 이론] 로그 기본성질과 밑변환 :: winner 로그의 기본성질과 밑변환에 대한 증명 위주로 설명을 하고자 합니다. 증명하는 과정에서 로그의 정의와 지수법칙에 대한 이해도를 높일 수 있기 … …
- Most searched keywords: Whether you are looking for [수2 이론] 로그 기본성질과 밑변환 :: winner 로그의 기본성질과 밑변환에 대한 증명 위주로 설명을 하고자 합니다. 증명하는 과정에서 로그의 정의와 지수법칙에 대한 이해도를 높일 수 있기 … 01. 로그의 기본성질과 밑변환을 시작하며… 로그의 기본성질과 밑변환에 대한 증명 위주로 설명을 하고자 합니다. 증명하는 과정에서 로그의 정의와 지수법칙에 대한 이해도를 높일 수 있기 때문에 반드시 스..
- Table of Contents:
티스토리툴바
![[수2 이론] 로그 기본성질과 밑변환 :: winner](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F2672DE4256D8DDB618)
데이터스케일링_로그변환
- Article author: challenge.tistory.com
- Reviews from users: 28857 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about 데이터스케일링_로그변환 데이터가 skew 되어 있으면 항상 log변환한다라고 거의 암기하듯 받아들였다. 다른 다양한 포스팅들을 보며 도대체 로그변환을 왜 하는 것인지 한번 … …
- Most searched keywords: Whether you are looking for 데이터스케일링_로그변환 데이터가 skew 되어 있으면 항상 log변환한다라고 거의 암기하듯 받아들였다. 다른 다양한 포스팅들을 보며 도대체 로그변환을 왜 하는 것인지 한번 … 데이터가 skew 되어 있으면 항상 log변환한다라고 거의 암기하듯 받아들였다. 다른 다양한 포스팅들을 보며 도대체 로그변환을 왜 하는 것인지 한번 알아보자. < 1. 로그스케일링 원리 > 출처 : bpapa.tistory.co..
- Table of Contents:
1 로그스케일링 원리
2 로그변환에 대한 고찰
3 로그변환 정말 옳은 방법일까
‘데이터분석&캐글’ Related Articles

데이터 분석 로그 변환
- Article author: velog.io
- Reviews from users: 23519 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about 데이터 분석 로그 변환 데이터 분석에서 log로 변환하는 경우가 있는데 이유는 무엇일까?목적부터 얘기하자면 log로 변환하는 이유는 정규성을 높이고 분석에서 정확한 값을 … …
- Most searched keywords: Whether you are looking for 데이터 분석 로그 변환 데이터 분석에서 log로 변환하는 경우가 있는데 이유는 무엇일까?목적부터 얘기하자면 log로 변환하는 이유는 정규성을 높이고 분석에서 정확한 값을 … 데이터 분석에서 log로 변환하는 경우가 있는데 이유는 무엇일까?목적부터 얘기하자면 log로 변환하는 이유는 정규성을 높이고 분석에서 정확한 값을 얻기 위함이다. 또 다른 말로 log의 역할은 큰 수를 같은 비율의 작은 수로 바꿔 주는 것이다. 복잡한 계산을 심플하게
- Table of Contents:
Skewness(왜도)와 Kurtosis(첨도)
Example
회귀분석을 할 때 로그 변환을 하는 이유 :: 저녁에 하는 데이터 공부
- Article author: evening-ds.tistory.com
- Reviews from users: 25908 Ratings
- Top rated: 4.5
- Lowest rated: 1
- Summary of article content: Articles about 회귀분석을 할 때 로그 변환을 하는 이유 :: 저녁에 하는 데이터 공부 미시데이터를 다루는 경우에는 로그임금을, 거시데이터는 로그GDP나 로그인구를 사용하는 경우가 꽤 많다. 계량경제학 서적은 로그변환 변수를 해석하는 … …
- Most searched keywords: Whether you are looking for 회귀분석을 할 때 로그 변환을 하는 이유 :: 저녁에 하는 데이터 공부 미시데이터를 다루는 경우에는 로그임금을, 거시데이터는 로그GDP나 로그인구를 사용하는 경우가 꽤 많다. 계량경제학 서적은 로그변환 변수를 해석하는 … 0. 들어가는 글 데이터 분석을 이용한 논문을 보다보면 변수에 로그를 취하는 경우가 종종 있다. 미시데이터를 다루는 경우에는 로그임금을, 거시데이터는 로그GDP나 로그인구를 사용하는 경우가 꽤 많다. 계량경..계량경제학과 머신러닝을 공부하고 포스팅합니다.
엑셀, 파이썬, R을 이용한 분석과 자동화를 합니다.이따금 잡다한 리뷰도 올립니다.
- Table of Contents:
0 들어가는 글
1 단위(Scale)의 문제
2 모형(Model)의 문제
3 데이터 생성 과정(Data Generating Process;DGP)의 문제
4 마치며
TAG
관련글 관련글 더보기
인기포스트
티스토리툴바

한 권으로 다지는 머신러닝&딥러닝 with 파이썬: 인공지능 핵심 개념과 사용 사례 … – 알베르토 아르타산체스, 프라틱 조시 – Google Sách
- Article author: books.google.com.vn
- Reviews from users: 12715 Ratings
- Top rated: 4.3
- Lowest rated: 1
- Summary of article content: Articles about 한 권으로 다지는 머신러닝&딥러닝 with 파이썬: 인공지능 핵심 개념과 사용 사례 … – 알베르토 아르타산체스, 프라틱 조시 – Google Sách Updating …
- Most searched keywords: Whether you are looking for 한 권으로 다지는 머신러닝&딥러닝 with 파이썬: 인공지능 핵심 개념과 사용 사례 … – 알베르토 아르타산체스, 프라틱 조시 – Google Sách Updating 인공지능이 처음이라면! 개념과 예제로 머신러닝 탄탄하게 다지기 이 책은 인공지능 관련 핵심 개념부터 머신러닝과 딥러닝까지, 인공지능 구현에 필요한 모든 것을 담았다. 실제 시나리오를 살펴보면서 문제에 따라 어떤 알고리즘을 어떻게 적용하는지 학습한다. 예제는 파이썬과 텐서플로를 사용하며 파이썬 입문자도 쉽게 따라 할 수 있는 코드로 구성되었다. 파이썬 프로그래밍 경험이 있다면 코드를 자유롭게 활용해 원하는 프로그램을 만들어볼 수 있다. 영화 추천 시스템 구축, 주식시장 분석, 객체 추적기 구축 등 흥미로운 예제를 따라 차근차근 학습하고 나면 다양한 인공지능 기술을 이해하고 상황에 맞춰 자신 있게 적용하는 자신을 발견하게 될 것이다. 이미지, 텍스트, 음성 등 다양한 데이터를 이해하는 똑똑한 애플리케이션을 지금 바로 만들어보자. 대상 독자인공지능을 배우고 싶은 누구나인공지능을 사용해 실제 애플리케이션을 개발하려는 파이썬 개발자다루는 내용인공지능, 머신러닝, 딥러닝이 무엇인지 이해한다.주요 인공지능 사용 사례를 살펴본다.머신러닝 파이프라인 구축 방법을 학습한다.특성 선택과 특성 공학의 기본 개념을 이해한다.지도 학습과 비지도 학습의 차이점을 이해한다.인공지능을 개발하는 최신 클라우드 기술과 도구를 살펴본다.자동 음성 인식 시스템과 챗봇을 만들어본다.인공지능 알고리즘을 시계열 데이터에 적용한다.인공지능 초보 여행자에게 나무가 아닌 숲을 보여주는 완벽한 안내서! 알파고, 넷플릭스, 애플 시리는 인공지능이 사용된 대표적인 사례입니다. 인공지능 기술을 아는 사람이든 모르는 사람이든 누구나 일상에서 심심찮게 접할 수 있죠. 한편으로는 우리도 모르는 사이에 인공지능이 한몫을 톡톡히 하고 있는 사례도 있습니다. 구글 검색과 쿠팡 배송 시스템이 그 예입니다. 우리는 이를 통해 인공지능이 이미 일상에 깊숙이 자리 잡았음을 알 수 있습니다. 이것이 바로 이 책의 출발점입니다. 이 책은 독자가 일상 속 친숙한 사례로부터 인공지능 학습의 첫발을 내딛도록 안내합니다. 대표적인 사용 사례들을 먼저 소개한 뒤에 각 기술을 구현하려면 어떤 알고리즘을 어떻게 적용해야 하는지 차근차근 알려줍니다. 머신러닝과 딥러닝의 핵심 개념들을 너무 얕지도, 너무 어렵지도 않게 설명해 기본기를 탄탄히 다지도록 해줍니다. 영화 추천 시스템, 게임 봇, 텍스트 감정 분석기 등을 구축하는 흥미로운 예제도 함께합니다. 장별 주요 내용 [1장 인공지능 소개]인공지능 애플리케이션을 구축하는 데 필요한 핵심 개념을 학습합니다. 파이썬 3 설치 방법도 알아봅니다. [2장 인공지능 사용 사례]인공지능 알고리즘을 살펴보기에 앞서 오늘날 가장 많이 사용되는 분야와 사용 사례를 분석합니다. [3장 머신러닝 파이프라인]머신러닝 파이프라인이 무엇인지 학습하고 구현에 어떤 도구가 사용되는지 알아봅니다. 파이프라인 내 주요 단계를 예제와 함께 살펴봅니다. [4장 특성 선택과 특성 공학]특성 선택과 특성 공학이 무엇이며 왜 중요한지 학습합니다. 기존 특성과 외부 소스에서 새 특성을 만드는 방법과, 중복되거나 가치가 낮은 특성을 제거하는 방법을 알아봅니다. [5장 지도 학습을 이용한 분류와 회귀]지도 학습이 무엇이며 비지도 학습과 어떤 차이가 있는지 알아봅니다. 분류가 무엇인지 학습하고 다양한 알고리즘을 살펴봅니다. [6장 앙상블 학습을 이용한 예측 분석]다양한 앙상블 방법과 각 방법을 언제 사용하는지 학습합니다. 배운 내용을 예제에 적용해 교통량을 예측해봅니다. [7장 비지도 학습을 이용한 패턴 감지]비지도 학습과 데이터 클러스터링 개념을 학습합니다. 다양한 클러스터링 알고리즘을 적용하는 방법을 알아보고 예제를 통해 작동 방식을 이해합니다. [8장 추천 시스템 구축]추천 시스템 구축에 필요한 개념을 학습하고 이를 활용해 영화 추천 시스템을 구축해봅니다. [9장 논리 프로그래밍]논리 프로그래밍으로 프로그램을 작성하는 방법을 배웁니다. 가계도 구문 분석, 지도 분석, 퍼즐 솔버 구축 등 문제 해결 예제를 살펴봅니다. [10장 휴리스틱 검색 기술]휴리스틱 검색의 정의와 검색 기술을 학습합니다. 예제를 통해 영역 색상 문제를 해결하고 8-퍼즐 솔버와 미로 찾기를 구축해봅니다. [11장 유전 알고리즘과 유전 프로그래밍]유전 프로그래밍이 AI 분야에서 중요한 이유를 알아봅니다. 유전 알고리즘을 사용해 간단한 문제를 해결하는 방법을 학습한 뒤 실제 문제에 적용해봅니다. [12장 클라우드를 이용한 인공지능]AI 프로젝트를 활성화하고 가속화하는 다양한 클라우드 제공 업체 및 제품을 알아봅니다. [13장 인공지능을 이용한 게임 개발]다양한 검색 알고리즘을 학습하고 마지막 동전 남기기, 틱택토, 커넥트포, 헥사폰 게임을 플레이하는 지능형 봇을 구축해봅니다. [14장 음성 인식 구축]음성 데이터를 처리하고 특성을 추출하는 방법을 배웁니다. 추출한 기능을 사용해 음성 인식 시스템을 구축해봅니다. [15장 자연어 처리]자연어 처리에 사용하는 다양한 기술을 학습합니다. 배운 내용을 활용해 카테고리 예측기, 성별 식별자, 감정 분석기를 구축해봅니다. [16장 챗봇]챗봇 구축에 필요한 기본 개념과 도구를 살펴본 뒤 이를 기반으로 챗봇을 구축해봅니다. [17장 시퀀스 데이터와 시계열 분석]시퀀스 데이터의 다양한 특성을 살펴보고 은닉 마르코프 모델을 사용해 시퀀스 데이터를 분석하는 방법을 학습합니다. 배운 내용을 활용해 주식시장 데이터를 분석해봅니다. [18장 이미지 인식]이미지 인식의 중요성을 알아보고 라이브 영상에서 물체를 감지 및 추적하는 방법을 학습합니다. 얼굴과 눈을 감지하고 추적하는 예제를 살펴봅니다. [19장 신경망]신경망을 구축하고 훈련하는 방법을 학습합니다. 퍼셉트론이 무엇이며 신경망 구축에 어떻게 사용되는지 알아봅니다. 마지막에는 광학 문자 인식 엔진을 구축해봅니다.[20장 합성곱 신경망을 이용한 딥러닝]딥러닝의 기본을 학습합니다. 합성곱 신경망에 관련된 다양한 개념을 살펴보고 이를 이미지 인식에 사용하는 방법을 알아봅니다. 학습한 내용을 기반으로 실제 애플리케이션을 구축해봅니다. [21장 순환 신경망과 기타 딥러닝 모델]자연어 처리 및 이해에 자주 사용되는 순환 신경망을 학습합니다. 순환 신경망 아키텍처를 살펴보고 어떤 이점과 제한 사항이 있는지 알아본 뒤 간단한 예제를 살펴봅니다.[22장 강화 학습 – 지능형 에이전트 생성]강화 학습의 정의와 모델 내 구성 요소를 살펴봅니다. 강화 학습 시스템을 구축하는 데 사용하는 기술과 학습 에이전트를 구축하는 방법을 알아봅니다. [23장 인공지능과 빅데이터]빅데이터 기술을 적용해 머신러닝 파이프라인을 가속화하는 방법을 알아보고 데이터 세트 수집, 변환, 유효성 검사를 간소화하는 기술을 분석합니다. 아파치 스파크를 사용하는 예제를 살펴봅니다.
- Table of Contents:
Log Transformation 로그/지수/제곱/루트/역수 함수변환 [빅공남! 통계 같이해요] – 빅공남 빅데이터 공부하는 남자
- Article author: seeyapangpang.tistory.com
- Reviews from users: 29854 Ratings
- Top rated: 3.4
- Lowest rated: 1
- Summary of article content: Articles about Log Transformation 로그/지수/제곱/루트/역수 함수변환 [빅공남! 통계 같이해요] – 빅공남 빅데이터 공부하는 남자 Log Transformation 로그 지수 루트 역수 제곱 변환 등 데이터의 변수 변환 기법 중에 하나인 함수 변환에 대해서 같이 공부하는 포스팅과 유튜브 … …
- Most searched keywords: Whether you are looking for Log Transformation 로그/지수/제곱/루트/역수 함수변환 [빅공남! 통계 같이해요] – 빅공남 빅데이터 공부하는 남자 Log Transformation 로그 지수 루트 역수 제곱 변환 등 데이터의 변수 변환 기법 중에 하나인 함수 변환에 대해서 같이 공부하는 포스팅과 유튜브 … Log Transformation 로그 지수 루트 역수 제곱 변환 등 데이터의 변수 변환 기법 중에 하나인 함수 변환에 대해서 같이 공부하는 포스팅과 유튜브 영상을 준비했습니다. 특히, 로그 변환은 Data의 Skew를 조절하..
- Table of Contents:
![Log Transformation 로그/지수/제곱/루트/역수 함수변환 [빅공남! 통계 같이해요] - 빅공남 빅데이터 공부하는 남자](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbp1ufG%2Fbtrxqb9h0Vi%2Fw8EEwVSGqtcW3kNhRLMVmK%2Fimg.png)
데이터가 뛰어노는 AI 놀이터, 캐글: 상위 랭킹 진입을 위한 필살기 – 가도와키 다이스케, 사카타 류지, 호사카 게이스케, 히라마쓰 유지, 대니얼WJ – Google Sách
- Article author: books.google.com.vn
- Reviews from users: 5029 Ratings
- Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about 데이터가 뛰어노는 AI 놀이터, 캐글: 상위 랭킹 진입을 위한 필살기 – 가도와키 다이스케, 사카타 류지, 호사카 게이스케, 히라마쓰 유지, 대니얼WJ – Google Sách Updating …
- Most searched keywords: Whether you are looking for 데이터가 뛰어노는 AI 놀이터, 캐글: 상위 랭킹 진입을 위한 필살기 – 가도와키 다이스케, 사카타 류지, 호사카 게이스케, 히라마쓰 유지, 대니얼WJ – Google Sách Updating 데이터 분석 무한 경쟁 ‘캐글’에서 살아남기 위한 비결 세계 최대 규모 데이터 분석 경진 대회 플랫폼인 캐글에서는 일반적이지 않은 데이터 처리 기법이 많이 활용된다. 이를 이해하고 체득하여 활용하는 것은 대회뿐만 아니라 데이터 분석 실무에서도 모델 정확도를 높이는 데 매우 유용하다. 특징(feature)을 만드는 방법, 앙상블, 평가지표, 사이킷런, xgboost 등 기존에는 잘 다루지 않았던 기법과 사례를 이 책 한 권에 정리했다. 경진 대회에 참여할 계획이 있거나, 캐글을 경험해봤지만 더 높은 상위 랭킹에 도전하고 싶다면 지금 바로 읽어보기를 권한다. 주요 내용 정밀도가 높은 모델 구축하기데이터에서 특징 추출하기변수를 변환해 특징 생성하기평가지표를 이용해 예측 결과 최적화하기하이퍼파라미터 튜닝여러 모델을 조합해 예측하는 앙상블 기법과 스태킹(stacking)시계열 데이터 종류와 취급 방법 추천사 캐글 시작에 앞서 든든한 책 한 권이 있어야 한다면 이 책을 추천합니다. 저자가 상당한 내공을 모아 든든한 한 권으로 묶어낸 만큼 다 소화한다면 데이터 관련 대회들이 조금은 쉽게 느껴질 겁니다. 최근 진행 중인 캐글 대회에도 이 책을 적극적으로 활용하면 좋은 성과를 얻을 수 있으리라 생각합니다._Heroseo, Kaggle Notebooks Master 머신러닝 기초를 공부하고 캐글에 이제 막 발을 내딛는 사람과 캐글 경험이 있지만 대회 코드 작성에 어려움을 느낀 사람에게 훌륭한 길잡이 역할을 해줍니다. 상위권에 랭크된 노트북의 솔루션을 꼼꼼하게 리뷰해준 덕분에 여러 대회에 다양한 기법으로 접근해볼 수 있습니다._신홍재, 학생 머신러닝을 가장 빨리, 재미있게 학습하는 방법은 캐글 대회에 참여하는 것이라 생각합니다. 그렇지만 입문 대회라도 생각보다 점수를 올리기가 쉽지 않고 대회마다 평가 기준이 달라 입문자로서는 벽이 높게 느껴집니다. 이러한 어려움을 이 책에서는 매우 친절하고 쉽게 설명합니다._김태헌, DB Inc. 흔히 사용하거나 검색으로 쉽게 찾을 수 있는 방법론 외에 다양한 대안들을 소개하는 유니크한 도서입니다. 특히 각 기법에 대해 상세한 수식과 예제 코드를 함께 제시하여 이해와 활용성을 동시에 잡아 백과사전과 같이 유용합니다. 기본 이론, 방법론 학습은 완료했지만 캐글 상위권 공략을 위해 아직 2% 부족하다고 느껴지는 분들에게 추천합니다._김사무엘, 데이터사이언스랩 캐글에 처음 도전할 때 가장 어려운 점은 자신이 수행할 수 있는 스킬과 대회에서 필요한 스킬의 단계 차이가 크게 나는 것이라고 생각합니다. 이 책은 머신러닝 기초부터 다양한 대회에서 기법이 실제로 적용되는 부분까지 세세하게 알려주기 때문에 많은 데이터를 직접 만지며 스킬의 단계 차이를 줄일 수 있습니다._이창우, 학생 캐글 최신 트렌드에 뒤처지지 않으면서도 번역상의 문제로 이해가 되지 않는 부분이 없었습니다. 캐글에 관심 있는 분은 물론 실무에서 직접 캐글 코드를 참고하여 모델링을 고려하는 분에게도 추천합니다._곽두일, 큐브엔시스 인공지능사업본부 본부장, 바벨 AI 대표캐글 상위 랭킹 진입에 필요한 필살기를 한 권에 정리했다! 상당수의 데이터 과학자가 자신의 실력을 검증하고자 ‘캐글’에 도전합니다. 대회에서는 실제 데이터를 이용하기 때문에 일반적이지 않은 데이터 처리 방법과 기법이 많이 활용됩니다. 그러한 내용을 이해하고 스스로 활용할 수 있는 능력을 갖추는 것은 경진 대회는 물론이고 실무에서도 모델을 구현하는 데 많은 도움이 됩니다. 최대한 많은 기술과 사례를 한 권에 담기 위해 노력했습니다. 정형 데이터를 다루는 대회를 대상으로 하여 문제 설정이 명확하게 주어진 가운데 성능이 높은 모델을 만들려면 어떻게 해야 하고 무엇을 주의해야 할지에 초점을 맞추었습니다. 특히 특징을 생성하는 방법, 검증, 파라미터 튜닝 등 다른 도서에서는 잘 다루지 않는 노하우나 포인트도 설명합니다. 처음부터 전부 이해하려 하기보다는 우선 빠르게 읽으면서 관심 있는 부분만 집중적으로 읽는 것을 권합니다. 또는 대회 도중에 힌트가 필요할 때 살짝 보거나 헷갈리는 부분을 사전적으로 참조하여 읽어도 좋습니다. 캐글에 도전하고 싶지만 어떻게 해야 할지 막막하거나, 매번 같은 방법만 사용하여 다른 방법도 알고 싶거나, 더 높은 순위권에 진입하는 것이 목표라면 꼭 읽어야 하는 책입니다. 경진 대회에서 쓰이는 기술은 실무에도 유용하므로 대회에 흥미가 없어도 읽으면 도움이 될 것입니다.
- Table of Contents:
See more articles in the same category here: 180+ tips for you.
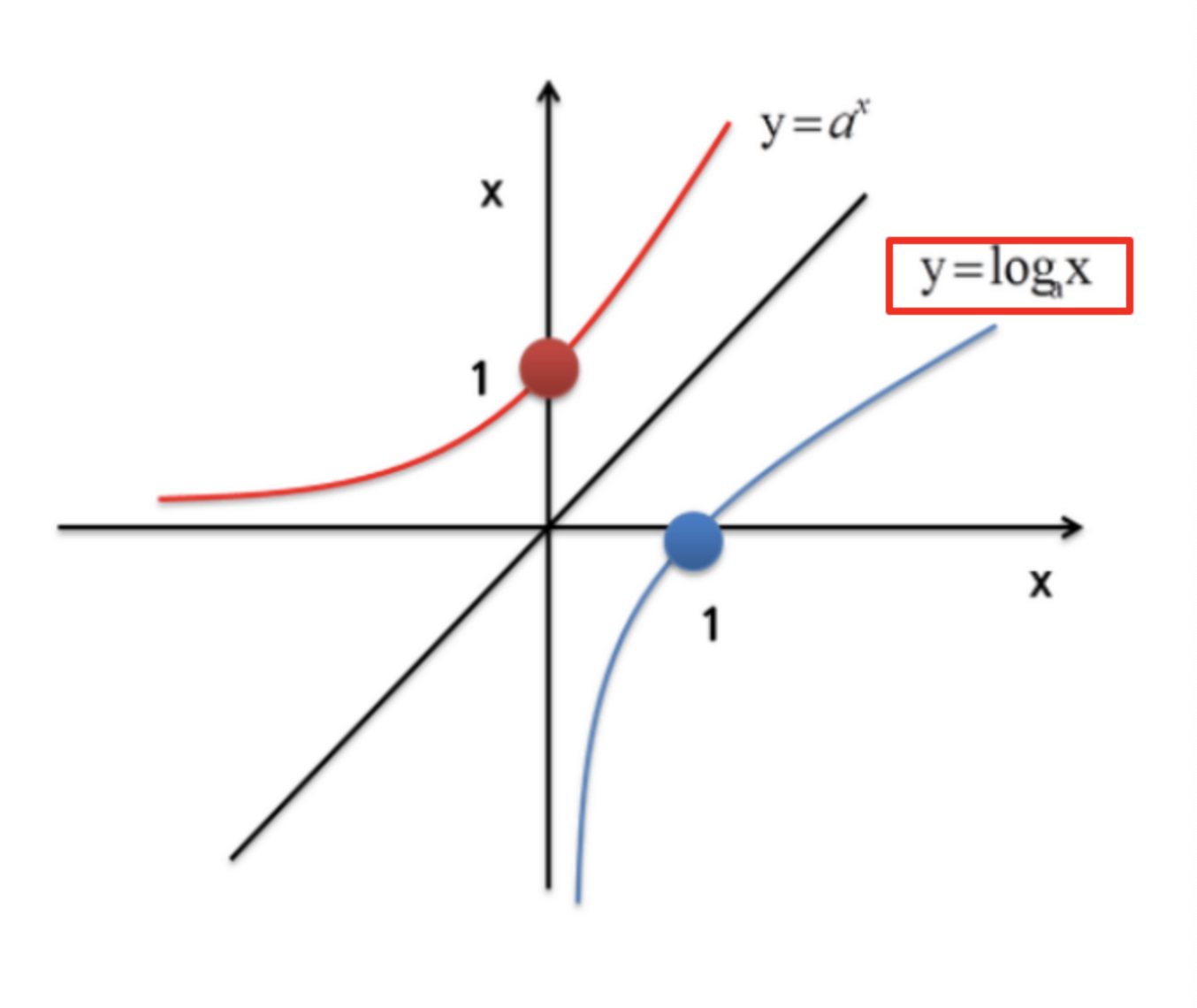
로그의 밑 변환 공식
로그의 밑 변환 공식이에요. 로그에서 밑은 log 옆에 작게 쓰는 걸 말하죠? 이걸 변환시킬 수 있는 공식이에요. 이름 그대로 공식이니까 외워야겠죠?
이 로그의 밑 변환 공식을 알고 있어야 다음에 공부할 로그의 성질 두 번째도 이해할 수 있어요. 로그의 밑 변환 공식을 이용해서 로그의 성질 두 번째를 유도할 거니까요.
밑의 변환 공식을 잘 알아두면 로그의 계산을 할 때 조금 더 편리해져요. 어려운 공식은 아니고 두 개만 할 거니까 잘 봐두세요.
로그의 밑 변환 공식
로그의 밑 변환 공식은 원래 있던 로그의 밑을 새로운 밑으로 바꿀 때 원래 로그의 모양이 어떻게 바뀌는지를 공식으로 나타낸 거예요.
ax = b를 로그로 변환해보죠.
ax = b ⇔ log a b = x …… ①
ax = b의 양변을 c(c > 0, c ≠ 1)을 밑으로 하는 로그를 취해보죠.
두 번째 줄에서 진수의 지수는 로그 앞으로 가져올 수 있는 로그의 성질을 적용했어요.
세 번째 줄에서 a ≠ 1이므로 log c a ≠ 0이에요. 따라서 양변을 log c a로 나눌 수 있어요.
네 번째 줄은 ①에서 log a b = x니까 식에 대입했어요.
어떤가요? 분수 꼴로 되었는데, 분모, 분자 모두 밑은 c라는 새로운 밑이에요. 분모에 있는 로그의 진수는 a, 분자에 있는 로그의 진수는 b고요. 원래 로그의 밑과 진수를 밑이 같은 새로운 로그의 나눗셈으로 바꿀 수 있다는 뜻이에요.
새로운 밑으로 사용할 숫자 c는 1이 아닌 양수라면 어떤 숫자도 괜찮아요. 가능하면 새로운 로그로 바꿨을 때 원래 로그의 밑과 진수를 없애고 실수로 바꿀 수 있는 수를 사용하면 좋지요. a, b가 거듭제곱일 때 c는 소인수를 사용하면 좋아요.
예를 들어, a = 4, b = 8이라면 a = 22, b = 23이니까 c는 a, b의 소인수인 c = 2를 사용하는 거죠.
a = 27, b = 81이라면 a = 33, b = 34니까 c = 3을 사용하고요.
이번에는 ax = b의 양변을 b(b > 0, b ≠ 1)를 밑으로 하는 로그를 취해보죠.
두 번째 줄의 좌변에서 진수의 지수는 로그 앞으로 가져올 수 있는 로그의 성질을 적용했어요. 우변에서 밑과 진수가 같으면 1이죠? log b b = 1
세 번째 줄에서 a ≠ 1이므로 log b a ≠ 0이에요. 따라서 양변을 log b a로 나눌 수 있어요.
네 번째 줄은 ①에서 log a b = x니까 식에 대입했어요.
원래 로그에서 밑과 진수를 바꾸고 역수를 취하면 원래 로그와 같다는 걸 알 수 있어요.
로그의 밑 변환 공식
a > 0, a ≠ 1, b > 0, c > 0, c ≠ 1일 때
첫 번째 밑 변환 공식에서 b = 1이 되어도 괜찮아요. 하지만 두 번째 역수를 취하는 공식에서는 b가 로그의 밑이 되어야 하니까 1이면 안 돼요. b ≠ 1
a는 두 공식 모두에서 로그의 밑이니까 a > 0, a ≠ 1이어야 하고요.
다음을 간단히 하여라.
(1) log 4 2
(2) log 2 3 × log 3 4
(1) 밑이 4, 진수가 2니까 4, 2의 소인수인 2를 밑으로 하는 새로운 로그를 취해보죠.
(2) 앞의 로그는 진수가 3, 뒤의 로그는 밑이 3이니까 로그의 역수를 취해서 계산해 볼까요?
함께 보면 좋은 글
로그란, 로그의 정의
로그의 성질, 로그의 성질 증명
지수법칙 – 실수 지수, 정수 지수, 유리수 지수 비교
지수함수, 지수함수의 그래프
정리해볼까요 로그의 밑 변환 공식
a > 0, a ≠ 1, b > 0, c > 0, c ≠ 1일 때
그리드형(광고전용)
[회귀분석] 로그 변환 (Log transformation)은 언제, 어떻게 쓰는가?
로그 변환은 언제 그리고 어떻게 쓰는가?
앞서 로그 변환에 대해서 다루어 보았는데, 변수의 변환이 새로운 입력과 출력 사이의 관계를 야기시킨다는 것은 명백해졌다. 종종 적합의 성능도 향상 시키고, 많은 응용된 회귀 문제에서 커다란 중요성을 가지기도 한다. 따라서, 언제, 어떻게 변환을 시키는가? 로그-시간 실용적인 경험은 몇몇 간단한 가이드라인으로 이끈다. 변수에 대한 로그 변환은 x에 하든, y에 하든 모델의 적합에 유용한데, 만약에 아래와 같은 조건이 있다면 말이다.
1. 회귀 선이 (0, 0)을 지나야 할 때, 입력과 출력 모두 로그 변환이 요구 된다.
2. 만약에 변수가 상대적인 스케일에 있을 때, 또는 퍼센트로 된 스케일에 있다면 로그 변환이 요구 된다.
3. 변수들이 왼쪽 끝에서 0이고, 오른쪽에서는 이론적으로 임의의 큰 값을 상대적인 스케일에서 가질 때
4. 만약에 변수에 대한 말지널 분포가 우리가 히스토그램으로부터 관찰할 수 있듯이, 명백하게 오른쪽으로 기울어져 있다면, 이것은 종종 상대적인 스케일에서의 양수의 변수의 케이스가 되고, 따라서, 로그 변환이 요구 된다.
요약하자면, 나는 감히 말하기를 로그 변환은 거의 우리가 선형 모델을 이야기 할 때, 예외 사항이 아니라, 아주 흔한 것이라고 할 수 있다. 반면, 변환이 잘못되거나, 가능하지 않은 경우도 있다. 모든 변수들이 음수의 값을 가질 때, 우리는 문제에 봉착한다. 이유는 로그는 엄격하게 양수의 영역에서만 유효하기 때문이다. 요약하면 아래와 같다.
1. 음수 값을 가지는 입력과 출력 변수에 대해서, 로그 변환과 로그-로그 모델은 적합하지 않다.
2. y = 0 또는 x = 0가 나타나는 경우, 로그 변환은 여전히 가능하지 않고, 분석으로부터 이러한 데이터를 제외하지 마라. 이것은 시스템적인 에러를 야기할 것이다. 우리가 할 수 있는 것은 변수를 천이시키는 것이다. x <- x + c 3. 위에서 보통 상수 c로 선택하는 것은 1이다. 그러나, 이것은 회귀 모델이 더 이상 스케일 변환에 대해서 불변하지 않다는 것을 의미한다. 따라서, 추천하기를 c를 0보다 큰 아주 작은 값으로 하는 것을 추천한다.
데이터가 skew 되어 있으면 항상 log변환한다라고 거의 암기하듯 받아들였다.
다른 다양한 포스팅들을 보며 도대체 로그변환을 왜 하는 것인지 한번 알아보자.
< 1. 로그스케일링 원리 >
출처 : bpapa.tistory.com/66
데이터 분석에서 log의 중요성에 대해서 이야기 해보겠다.
데이터 분석을 하기 위해 log를 취하는 이유는 한마디로 정규성을 높이고 분석(회귀분석 등)에서 정확한 값을 얻기 위함이다.
데이터 간 편차를 줄여 왜도(skewness)와 첨도(Kurtosis)를 줄일 수 있기 때문에 정규성이 높아진다.
예를 들어, 연령 같은 경우에는 숫자의 범위가 약 0세~120세 이하 이겠지만, 재산 보유액 같은 경우에는 0원에서 몇 조단위까지 올라갈 수 있다. 즉, 데이터 간 단위가 달라지면 결과값이 이상해 질 수 있다.
: log 변환은 1/ 큰 수를 작게 만들 경우 2/ 복잡한 계산을 간편하게 위할 경우 사용된다.
로그를 취하는 순간 그 수는 진수가 되어버리니, 값이 작아지고
로그의 성질에 따라 곱셈은 진수의 덧셈으로 나누기는 뺄셈으로 바뀐다.
[큰수를 작게 만들 경우]예를 들어 , 100= 10^2 이다 . 100에 상용로그를 취한다면 100을 10을 밑으로 하는 지수가 있는 값의 그 지수로 나타낸다 .
그래서 100에 상용로그를 취하면 2가 된다 .
[복잡한 계산을 간편하게 만들 경우]l o g 10 또한 로그를 취하면 로그의 성질에 의해 곱하기가 더하기로, 나누기가 빼기로 바뀐다 .
결론적으로 식에 로그릴 취하는 이유는 큰 수를 작게 만들고, 복잡한 계산을 쉽게 만들고, 왜도와 첨도를 줄여서 데이터 분석 시 의미있는 결과를 도출하기 위한 것이다.
위의 재산 보유액 예와 같이 분석하려는 데이터 간의 편차가 큰 경우에 로그를 취하면 의미있는 결과를 얻을 가능성이 높아진다.
아래 차트에도 나와 있듯이 로그를 취하면 큰 값은 작아지는 것을 볼 수 있다.
위 포스팅으로 느낌을 잡았다면
‘로그스케일링 원리’를 피부로 느껴보자.
로그 값을 취할 경우 큰 수에 대한 간격이 좁아지기 때문에
데이터 간 간격이 클 경우 유용하게 작용할 수 있다.
> 밑을 10으로 하는 로그는 10제곱 수 단위로 작동한다. (cf.상용로그가 아닌 자연로그를 취하는 경우도 봄)
따라서 10~100 구간의 ‘제곱 단위 차이’는 ‘정수’로,
동일 제곱 수 단위 안에서의 값 차이는 소숫점자리로 나타나게 된다.
ex. log13 = 1.11394335231
log113 = 2.05307844348
위 이미지 링크 영상을 보면 더 자세히 로그변환에 대해 느낌을 잡을 수 있을 것이다.
(왼)로그변환 전 (오)로그변환 후 _https://inuplace.tistory.com/561
로그변환은 꼭 정규분포 변환에 한정되지 않음을 보여준 좋은 예시.
1960년대의 큰 차이를 보는 값들은 log로 인해 그 차이의 스케일이 작아지고 (ex 제곱단위의 정수 변화)
1970~2010의 값도 log변환으로 스케일이 작아졌지만 60년 값에 비해 그 폭이 작다. (ex 제곱 안 수의 소수자리 변화)
따라서 전체 스케일이 평준화되도록 각 값들이 작아졌기 때문에 분석이 용이해졌다.
출처: https://evening-ds.tistory.com/31 [저녁에 하는 데이터 공부]
< 2. 로그변환에 대한 고찰 >
회귀분석을 하다보면, 또는 회귀분석을 한 논문을 보다보면 변수에 로그를 취하는 경우가 종종 있다. 사실 꽤 많이 있다. 보통 노동경제학 논문에서 임금이나 소득을 쓰는 경우엔 여지없이 로그임금 또는 로그소득을 쓰고, GDP나 인구를 변수로 쓰는 경우도 로그GDP나 로그인구를 사용하는 경우가 꽤 많다. 계량경제학 서적을 보다보면 로그를 취한 변수를 해석하는 방법이 따로 있을 정도로 로그변환이 분명 중요하긴 하다. 하지만 그 중요성에 비해서 로그변환에 대해 자세히 설명하는 게 조금 부족하기는 하다. 예를 들어 ‘로그를 써야 하는 경우가 있는걸까?’, ‘변수에 로그변환을 해야 하는 규칙 같은 게 있는 걸까?’, ‘어떤 경우에 로그를 쓰고, 어떤 경우에는 변환을 하지 않을까?’와 같은 질문에 답을 바로 내리기가 어렵다.
결론적으로, 그런 법칙은 없는 것 같다. 아마 그래서 따로 설명이 안되어 있는 것은 아닌가 싶기도 하다. 다만 로그를 쓰는 게 더 나은 경우들은 있다. 비록 의무적으로 변환을 해야 하는 건 아니더라도. 다만, 이 내용은 경험적으로 또는 지도를 받으며 은연중에 알게 된 사실들이다보니 공인된 지식이라고 보기는 어렵다. 하지만 어느 정도 알아두면 교수님들의 공격(…)을 방어할 수단 중 하나는 될 수 있지 않을까 싶다. 그러기를 바라기도 하고.
아무튼 내 생각엔 대략 3가지 정도의 이유로 로그변환을 하는 것 같다.
1) 단위(Scale)의 문제
소득이 불평등에 미치는 영향에 관심이 있다고 해보자. 그러면 우리는 다음과 같은 생각을 하고 있다는 의미이다.
z는 다른 설명변수 벡터를 말한다. 소득이 불평등에 미치는 효과를 추정하기 위해 선형식을 세운다고 해보자. 그리고 관심의 대상을 구체적으로 지역단위로 좁혀보자.
그러면 이제 관심사가 지역별 소득이 지역별 불평등에 미치는 영향으로 좁혀지고서 다음과 같은 선형식을 생각할 수 있다.
z는 GRDP가 아닌 변수들의 벡터, βz는 다른 변수들의 계수를 모아둔 벡터를 말한다. 지역별 소득은 GRDP로, 지역별 불평등은 지니계수로 통제한다고 가정했다. 자, 이제 이 식을 추정한 결과 우리의 관심대상인 β1이 X로 추정되었다고 해보자(예를 들어 0.0001이나 0.8213 이런 숫자).
그러면 우린 이걸 이렇게 해석한다. “다른 조건이 일정할 때 GRDP가 한 단위 늘어나면 지니계수는 평균적으로 X만큼 상승한다/하락한다.”라고.
여기서 잠깐. GRDP가 한 단위 상승한다는 건 무슨 의미인가. 만약 우리가 GRDP를 천원, 백만원 같은 단위가 아니라 ‘원’으로 측정했으면 GRDP가 1원이 늘어나면 지니계수가 XX만큼 변한다는 의미이다. 이 값이 0.0001이라면, GRDP를 10,000원만 늘어나면 지니계수는 1이 증가한다. 이 값이 0.001이라면, GRDP가 1,000원만 늘어나도 지니계수는 1이 증가한다.
당연히 상식적으로 말이 안된다. 상식적인 결과는 GRDP를 표기한 숫자가 매우 크다면 추정되는 계수의 값은 매우 작게 나올 것이라고 짐작해볼 수 있다. 예를 들어 0.00000001 정도로 작게 나와서 ‘GRDP가 1원 증가하면 지니계수는 0.00000001증가한다’와 같이.
이처럼 변수의 숫자가 너무 커서(= 측정 단위가 너무 작아서) 추정되는 계수의 값이 너무 작다면 보기도 안 좋을 뿐더러, 무엇보다 해석하기가 어렵다. 보통은 이런 문제를 해결하고자 적당히 단위를 조정해준다. 예를 들어 백만원 단위, 십억원 단위처럼 큰 측정단위의 GRDP로 추정한 결과를 사용하고는 한다. 그렇게 되면 GRDP 1단위는 백만원 또는 십억원일테고, 이를 표기한 숫자는 상대적으로 작아질테니 보다 해석이 쉽고 와닿는 값으로 추정될 수 있다.
단위를 조정하는 다른 방식으로 표준편차로 나눠주기도 하는데, 이 경우는 해석이 너무 까다로워진다. 그래서 로그를 취하고는 한다. 로그는 태생이 큰 값을 작게 만들어 주는 방식이므로 적합하기도 하고 측정단위를 키우는 것만으로는 해결하지 못한 부분을 해결해준다.
무슨 말이냐면, 아까 추정을 국가를 단위로 추정했다고 해보자. GRDP 대신 달러로 측정한 GDP를 사용하고 단위는 백만달러라고 해보자.
만약 그 때 추정한 결과가 0.02라면, 우리는 ‘다른 조건이 일정할 때 GDP가 백만달러 늘어난다면, 지니계수는 0.02만큼 상승한다.’라고 해석할 수 있다. 이 해석이 논리적으로 말은 된다.
그런데 이 결과가 모든 국가에서 일관성있고 설득력 있게 다가올까? 아마 아닐거다. GDP 한 단위인 백만달러가 미국이나 중국 같은 경제대국에 비해 아주 작은 나라에서는 매우 큰 단위이다. 평균적이라는 단서가 붙는다고 하더라도 모든 국가에서 동일한 해석을 하기에는 이번에는 측정단위가 너무 크다.
하지만 만약 ‘GDP가 1% 상승했을 때, 지니계수는 0.01 증가한다’와 같은 해석을 할 수 있다면 어떨까? 여전히 국가별 특성에 따라 결과를 받아 들이는 데는 차이가 있을 수는 있어도 해석은 그런대로 설득력을 갖는다.
이처럼 변수를 측정하는 단위가 매우 작아서 값이 지나치게 크게 되면 생기는 문제를 해결하면서 계수 해석의 문제까지 동시에 해결할 수 있기 때문에 로그변환을 해주고는 한다.
2) 모형(Model)의 문제
첫번째는 사실 선택의 문제이기도 하다. 앞서 밝힌 것처럼 측정단위가 너무 작다면 단위를 키워서 숫자 자체는 작게 만들어 주면 된다. 한 국가의 경제규모 등 국가별 특성에 따라 ‘한 단위’가 현실과 동떨어져있다고 느낀다면 다른 변수를 통제하면 일부분 해결할 수 있다. 물론 로그변환을 하는 게 훨씬 좋지만.
이에 반해 로그를 취하는 게 좋은 경우가 있다. 애초에 모형 자체가 로그를 취해야 하는 경우를 말한다. 예를 들어 중력모형이 있다. 중력 모형은 뉴턴의 중력방정식과 비슷한 형태를 띄는데, 두 물체 간의 중력을 나타내는 방정식은 아래처럼 생겼다.
G는 중력, M은 질량, D는 거리를 말한다. 말하자면 중력이라는 건 두 물체의 질량에 비례하고 거리에는 반비례한다는 의미이다. 이런 아이디어를 무역이나 외환의 교역량, 나아가 인구간의 교류(이민인구)을 설명할 때에도 사용한다. 즉 두 국가간 재화/인구 등의 교역량은 두 국가의 ‘경제적 질량’에 비례하고 거리에는 반비례한다는 거다. 그러니 아래와 같은 모형을 생각해볼 수 있다.
TT는 교역량, EMEM은 경제적 질량을 말한다. 국가의 경제규모가 커질수록 교역량이 늘어나고, 국가 간의 거리가 너무 멀다면 비용문제로 교역량은 줄어들테니, 상식적으로 말은 된다.
문제는 이 모형을 바로 추정하기가 어렵다는 거다. 그래서 이 경우에는 양변에 로그를 취한다. 그러면 아래와 같은 식이 나온다.
이제 적당한 선형식이 되었으니 추정하면 된다.
이런 경우와 비슷한 게 콥더글라스함수(Cobb-Douglas function)을 사용하게 되는 경우인데, 콥더글라스 생산함수는 아래와 같이 생겼다.
여기서 α+β=1이면 1차동차함수인데, 각각의 값을 추정하기 위해 양변에 로그를 취해서 가설검정을 하고는 한다. 이 경우 로그를 취하지 않으면 추정이 매우, 매우 어려워 질 수 밖에 없다.
3) 데이터 생성 과정(Data Generating Process;DGP)의 문제
이 경우는 알고 있으면 아는 척 하기 참 좋다(!). 이 부분은 로그변환을 해야 하는 이론적인 근거는 될 수 있겠다. 바꿔 말하면 경제학적인 이유보다는 수학적인 이유다.
보통 확률변수의 분포가 정규분포처럼 아름다운 종모양과는 달리 로그정규분포처럼 꼬리가 긴 분포가 생기는 경우가 있다. 항상 그런 것은 아닌데, 데이터 생성과정에서 일종의 조작(?)이 생겨서 그럴 수 있다.
예를 들어서 이 세상이 매우 발달하고 공정해져서 개인의 능력에 맞게 임금을 받을 수 있다고 해보자(최저임금제는 없다고 가정한다).
그런데 누군가 아주 심각한 트롤러가 있다(!). 이 사람을 고용하면 오히려 생산이 줄어 드는 경우이다. 이렇게 되면 임금을 지불하는 게 아니라 오히려 돈을 받아야겠다(!!). 하지만 그런 일은 일어나지 않는다. 상식적으로도, 경제학적으로도 임금이 0 이하로 떨어지지는 않기 때문이다.
이처럼 어떤 변수들은 양의 실수(Real number) 내에서만 정의되는 경우가 있다. 이런 변수를 설명변수로 통제하여 추정하는 경우 원칙적으로는 곧바로 OLS로 추정을 하면 안된다. 이 변수는 양의 실수만 값으로 취할 수 있다는 제약식을 두고 추정량을 새로 구해보고, 그 값이 OLS와 같다면 그 때 OLS를 써야한다. 만약 다르다면…
이런 문제를 피하고자 로그변환을 한다. 로그는 아래 그림처럼 정의역은 양수(Positive Real Number), 공역은 모든 실수(Real Number)이기 때문에 로그변환을 한 값은 제약식이 없는 실수이다.
로그함수(출처 : 위키백과)
따라서 로그변환을 한 변수는 그대로 OLS를 써도 무방하다. OLS추정량이 불편추정량(Unbiased Estimator)이거나 일치추정량(Consistent Estimator)인지는 별개의 문제이지만.
4) 마치며
로그변환을 하는 데에는 법칙은 없다고 했는데, 막상 3번째 이유를 보면 법칙이 있는 것 처럼 보인다. 사실 그렇다(!). 하지만 없다고 생각하는 게 낫다. 저걸 신경쓰기 시작하면 이제 변수가 음수가 아닌 이유를 DGP를 들어서 설명해야 한다. 그러지 말고, 남들이 그렇게 하는 데에는 다 이유가 있다고 생각하고 누군가 로그로 변환해서 추정했다면 그렇게 하자(!!). 그리고 만약 누군가 로그로 변환한 이유를 묻는다면 그제서야 위의 3가지 이유 중 하나를 적당히 들자(!!!).
(여담1) 간혹 ‘변수가 로그정규분포이기 때문에 로그변환을 해서 정규분포로 만들어준다’고 하기도 하는데, 적절한 답은 아니라고 생각한다. 변수가 로그정규분포에서 나오든, 카이제곱분포에서 나오든 가설검정 단계에서 중요한 건 추정량의 분포이지, 변수의 분포가 아니다. 로그변환을 함으로써 원래는 로그정규분포인 ‘추정량’을 정규분포로 만들어준다는 이야기라면 모를까, ‘변수’의 로그정규분포 여부는 그리 중요하지는 않다. 적어도 회귀분석을 할 때는.
3. 로그변환, 정말 옳은 방법일까?
논문 : www.ncbi.nlm.nih.gov/pmc/articles/PMC4120293/
논문 2줄 요약
1. 변환하면 결국 원본 데이터하고 값이 달라지는거다. 종종 로그변환 후 원본 데이터와 상관성이 떨어지는 경우가 있다.
2. 되도록이면 사용하지말고 다른 분석방법을 쓰자.
논문에서도 말하는 바 이지만,
원본의 데이터를 그대로 살리면서 데이터를 변환하는 것은 사실상 불가능하다.
심지어 로그를 취해 변환시켰는데, 원본 데이터의 성질을 그대로 가져오는 것은 더 힘든 일이다.(스케일링 자체가 성질변환)
하지만 전통적으로 값의 크기를 맞출 때, 계산을 편리하게 하기 위해 로그변환은 종종 사용되었고
변환을 하더라도 원본 데이터의 성질보존력이 뛰어나기 때문에 현재도 많이 사용되고 있다.
어느 정도 안정성이 확보된 스킬이기 때문에 아무 생각없이 사용하는 것이 아니라면 무방하다고 판단한다.
So you have finished reading the 로그 변환 topic article, if you find this article useful, please share it. Thank you very much. See more: 로그 변환 계산기, 로그변환 이유, 로그변환 r, 로그 밑변환, 머신러닝 로그 변환, 로그 지수 변환, 자연로그 변환, 시계열로그 변환