
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 페이지 랭크 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://toplist.maxfit.vn team, along with other related topics such as: 페이지 랭크 페이지랭크 나무위키, 페이지랭크 마르코프, Personalized PageRank 설명, PageRank 설명, 구글행렬, Networkx PageRank, 구글 랭킹 알고리즘, 래리페이지
페이지랭크(PageRank)는 월드 와이드 웹과 같은 하이퍼링크 구조를 가지는 문서에 상대적 중요도에 따라 가중치를 부여하는 방법으로, 웹사이트 페이지의 중요도를 측정하기 위해 구글 검색에 쓰이는 알고리즘이다. 이 알고리즘은 서로간에 인용과 참조로 연결된 임의의 묶음에 적용할 수 있다.
페이지랭크 – 위키백과, 우리 모두의 백과사전
- Article author: ko.wikipedia.org
- Reviews from users: 11526
 Ratings
Ratings - Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about 페이지랭크 – 위키백과, 우리 모두의 백과사전 Updating …
- Most searched keywords: Whether you are looking for 페이지랭크 – 위키백과, 우리 모두의 백과사전 Updating
- Table of Contents:
알고리즘 설명[편집]
같이 보기[편집]
외부 링크[편집]

‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘 – 조성문의 실리콘밸리 이야기
- Article author: sungmooncho.com
- Reviews from users: 14241 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about ‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘 – 조성문의 실리콘밸리 이야기 네이버 검색엔진의 문제점을 처음 지적한 글을 썼던 2년 전부터 이 블로그에 언젠가 한 번 써보고 싶었던 주제가 하나 있었다. 구글의 PageRank … …
- Most searched keywords: Whether you are looking for ‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘 – 조성문의 실리콘밸리 이야기 네이버 검색엔진의 문제점을 처음 지적한 글을 썼던 2년 전부터 이 블로그에 언젠가 한 번 써보고 싶었던 주제가 하나 있었다. 구글의 PageRank … 네이버 검색엔진의 문제점을 처음 지적한 글을 썼던 2년 전부터 이 블로그에 언젠가 한 번 써보고 싶었던 주제가 하나 있었다. 구글의 PageRank 알고리즘을 설명하는 것이다. 원리는 간단하지만 알고리즘을 설명하려고 하면 말이 길어질 것 같고 쉽게 설명할 수 있을까 싶어 블로그에 쓸까 말까 망설였는데, 그냥 한 번 시작해보려고 한다. “Google”이라는 230조원짜리 회사가 처음 시작된 곳이 바로 이…
- Table of Contents:
Published by Sungmoon Cho
Post navigation
38 thoughts on “‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘”

‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘 – 조성문의 실리콘밸리 이야기
- Article author: icim.nims.re.kr
- Reviews from users: 20808 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about ‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘 – 조성문의 실리콘밸리 이야기 ‘처음 몇 십 개’처럼 검색 결과를 나열하는 기준으로 그 웹페이지가 얼마나 중요한지를 나타내는 수치(지표)가 필요하다. PageRank는 페이지의 중요도를 … …
- Most searched keywords: Whether you are looking for ‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘 – 조성문의 실리콘밸리 이야기 ‘처음 몇 십 개’처럼 검색 결과를 나열하는 기준으로 그 웹페이지가 얼마나 중요한지를 나타내는 수치(지표)가 필요하다. PageRank는 페이지의 중요도를 … 네이버 검색엔진의 문제점을 처음 지적한 글을 썼던 2년 전부터 이 블로그에 언젠가 한 번 써보고 싶었던 주제가 하나 있었다. 구글의 PageRank 알고리즘을 설명하는 것이다. 원리는 간단하지만 알고리즘을 설명하려고 하면 말이 길어질 것 같고 쉽게 설명할 수 있을까 싶어 블로그에 쓸까 말까 망설였는데, 그냥 한 번 시작해보려고 한다. “Google”이라는 230조원짜리 회사가 처음 시작된 곳이 바로 이…
- Table of Contents:
Published by Sungmoon Cho
Post navigation
38 thoughts on “‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘”
그 알고리즘이 너무 매력적이었기에 그들은 구글을 세웠다 : 기술 : 미래&과학 : 뉴스 : 한겨레
- Article author: www.hani.co.kr
- Reviews from users: 46653 Ratings
- Top rated: 3.4
- Lowest rated: 1
- Summary of article content: Articles about 그 알고리즘이 너무 매력적이었기에 그들은 구글을 세웠다 : 기술 : 미래&과학 : 뉴스 : 한겨레 검색 알고리즘 페이지랭크에 대한 이야기. 페이지랭크. 출처: 위키미디어커먼스 Felipe Micaroni Lalli. 인터넷은 그 자체가 데이터다. …
- Most searched keywords: Whether you are looking for 그 알고리즘이 너무 매력적이었기에 그들은 구글을 세웠다 : 기술 : 미래&과학 : 뉴스 : 한겨레 검색 알고리즘 페이지랭크에 대한 이야기. 페이지랭크. 출처: 위키미디어커먼스 Felipe Micaroni Lalli. 인터넷은 그 자체가 데이터다. 한겨레, 한겨레 신문, 뉴스, 오피니언, 스페셜, 커뮤니티, 포토, 하니TV[권오성의 세상을 바꾼 데이터]
- Table of Contents:
서비스 메뉴
본문

페이지랭크
- Article author: velog.io
- Reviews from users: 26952 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about 페이지랭크 페이지들의 우선순위는 어떻게 결정하는 걸까요? 이번 시간에는 구글의 검색 알고리즘인 페이지랭크 알고리즘을 배우고 페이지랭크 알고리즘에서 발생할 … …
- Most searched keywords: Whether you are looking for 페이지랭크 페이지들의 우선순위는 어떻게 결정하는 걸까요? 이번 시간에는 구글의 검색 알고리즘인 페이지랭크 알고리즘을 배우고 페이지랭크 알고리즘에서 발생할 … Week5(Graph), Day 22. 검색 엔진에서는 그래프 어떻게 활용할까?
- Table of Contents:

PageRank
- Article author: www.secmem.org
- Reviews from users: 37071 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about PageRank 페이지랭크(PageRank)는 구글의 설립자로 널리 알려진 래리 페이지와 세르게이 브린이 개발한 알고리즘으로, 웹 문서의 중요도를 구할 때 사용합니다. …
- Most searched keywords: Whether you are looking for PageRank 페이지랭크(PageRank)는 구글의 설립자로 널리 알려진 래리 페이지와 세르게이 브린이 개발한 알고리즘으로, 웹 문서의 중요도를 구할 때 사용합니다. PageRank 페이지랭크(PageRank)는 구글의 설립자로 널리 알려진 래리 페이지와 세르게이 브린이 개발한 알고리즘으로, 웹 문서의 중요도를 구할 때 사용합니다. 이 포스트에서는 페이지랭크 알고리즘의 원리와 어떻게 작동하는지에 대해 다룹니다. 웹을 그래프 형태로 나타내기 PageRank 알고리즘에서는 월드 와이드 웹의 문서들을 노드로 대응시키고 문서에서 다른 문서로 넘어가는 하이퍼링크를 간선으로 대응시켜서, 유방향 그래프로 웹을 나타냅니다. 보통 이러한 그래프를 웹 그래프라고 합니다. 예를 들어, 이 글과 이 글이 레퍼런스한 문서들이 그래프의 노드에 해당하고, Reference로 넘어가는 하이퍼링크가 방향이 있는 그래프에서 간선에 해당합니다….
- Table of Contents:
웹을 그래프 형태로 나타내기
노드의 중요도 구하기
페이지랭크 알고리즘
PageRank의 응용
마무리

PageRank 알고리즘 이해하기 :: 눈가락★
- Article author: eyeballs.tistory.com
- Reviews from users: 6022 Ratings
- Top rated: 4.2
- Lowest rated: 1
- Summary of article content: Articles about PageRank 알고리즘 이해하기 :: 눈가락★ matrix 연산을 통해 페이지랭크 구현 참고 링크들. https://www.sleshare.net/ChenGengMa/a-hadoop-implementation-of-pagerank. …
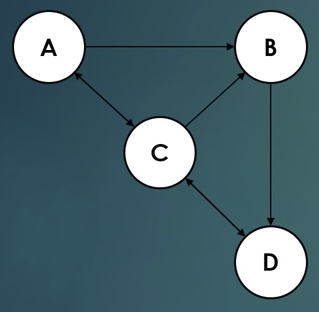
- Most searched keywords: Whether you are looking for PageRank 알고리즘 이해하기 :: 눈가락★ matrix 연산을 통해 페이지랭크 구현 참고 링크들. https://www.sleshare.net/ChenGengMa/a-hadoop-implementation-of-pagerank. 간단한 예를 통해 page rank 알고리즘을 이해해보기로 한다. 위와 같은 A,B,C,D 라는 인터넷 페이지가 있고, 각각의 페이지마다 서로를 향한 링크를 갖고 있다고 하자. 예를 들어 A 사이트에서는 B와 C로 가는 링..어서오세요.
시간을 담는 블로그입니다. - Table of Contents:
페이지랭크 알고리즘 (PageRank algorithm) — JOO’s LIBRARY
- Article author: joolib.tistory.com
- Reviews from users: 30225 Ratings
- Top rated: 4.2
- Lowest rated: 1
- Summary of article content: Articles about 페이지랭크 알고리즘 (PageRank algorithm) — JOO’s LIBRARY 구글 검색 엔진의 핵심인 페이지 랭크 알고리즘은 1998년 Sergey Brin 과 Lawrence Page의 논문 ‘The Anatomy of a Large-Scale Hypertextual Web … …
- Most searched keywords: Whether you are looking for 페이지랭크 알고리즘 (PageRank algorithm) — JOO’s LIBRARY 구글 검색 엔진의 핵심인 페이지 랭크 알고리즘은 1998년 Sergey Brin 과 Lawrence Page의 논문 ‘The Anatomy of a Large-Scale Hypertextual Web … 구글 검색 엔진의 핵심인 페이지 랭크 알고리즘은 1998년 Sergey Brin 과 Lawrence Page의 논문 ‘The Anatomy of a Large-Scale Hypertextual Web Search Engine’에서 등장했습니다. 논문에서는 design goal을 소..
- Table of Contents:
블로그 메뉴
공지사항
인기 글
태그
최근 댓글
최근 글
티스토리

페이지랭크 알고리즘 (PageRank algorithm) — JOO’s LIBRARY
- Article author: dbwodlf3.medium.com
- Reviews from users: 44527 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about 페이지랭크 알고리즘 (PageRank algorithm) — JOO’s LIBRARY 페이지 랭크 알고리즘(Page Rank Algorithm) … PageRank Algorithm은 페이지의 중요성을 측정하는 알고리즘으로서 페이지간의 Link를 분석하는 알고리즘 … …
- Most searched keywords: Whether you are looking for 페이지랭크 알고리즘 (PageRank algorithm) — JOO’s LIBRARY 페이지 랭크 알고리즘(Page Rank Algorithm) … PageRank Algorithm은 페이지의 중요성을 측정하는 알고리즘으로서 페이지간의 Link를 분석하는 알고리즘 … 구글 검색 엔진의 핵심인 페이지 랭크 알고리즘은 1998년 Sergey Brin 과 Lawrence Page의 논문 ‘The Anatomy of a Large-Scale Hypertextual Web Search Engine’에서 등장했습니다. 논문에서는 design goal을 소..
- Table of Contents:
블로그 메뉴
공지사항
인기 글
태그
최근 댓글
최근 글
티스토리
See more articles in the same category here: https://toplist.maxfit.vn/blog/.
위키백과, 우리 모두의 백과사전
페이지 랭크 알고리즘 개념도
페이지랭크(PageRank)는 월드 와이드 웹과 같은 하이퍼링크 구조를 가지는 문서에 상대적 중요도에 따라 가중치를 부여하는 방법으로, 웹사이트 페이지의 중요도를 측정하기 위해 구글 검색에 쓰이는 알고리즘이다. 이 알고리즘은 서로간에 인용과 참조로 연결된 임의의 묶음에 적용할 수 있다.
페이지랭크는 스탠퍼드 대학교에 재학 중이던 래리 페이지와 세르게이 브린이 새로운 검색 엔진에 대한 연구 기획의 일부로 개발한 것이다. 이 기획은 1995년 시작되어, 1998년 구글이라 불리는 시범 서비스로 발전하였다. 페이지와 브린은 페이지랭크에 기반한 검색 기술을 바탕으로 구글 사를 설립하였다.
알고리즘 설명 [ 편집 ]
페이지 랭크는 더 중요한 페이지는 더 많은 다른 사이트로부터 링크를 받는다는 관찰에 기초하고 있다. 예를 들어 페이지 A가 페이지 B,C,D 로 총 3개의 링크를 걸었다면 B는 A의 페이지 랭크 값의 1 3 {\displaystyle 1 \over 3} 만큼을 가져온다.
또한 페이지 랭크에서는 랜덤 서퍼(Random Surfer)라는 페이지를 임의로 방문하며 탐색하는 모델을 가정한다. 이 모델에서는 위 예의 A페이지를 방문한 서퍼는 A페이지를 보고 만족하여 탐색을 중단하거나, 혹은 A페이지에서 만족하지 못하여 다른 페이지를 방문할 것이다. 이러한 확률(Damping Factor)을 α {\displaystyle \alpha } 라 한다면, B페이지는 α ∗ 1 3 {\displaystyle \alpha *{1 \over 3}} 만큼 페이지 랭크를 받게 된다.
페이지 랭크는 이와 같은 방법을 통해 페이지간 페이지 랭크 값을 주고 받는 것을 반복하다보면, 전체 웹 페이지가 특정한 페이지 랭크 값을 수렴한다는 사실을 통해 각 페이지의 최종 페이지 랭크를 계산한다.
이 과정에서 구글 행렬(Google matrix)이 사용된다.
같이 보기 [ 편집 ]
‘쉽게 설명한’ 구글의 페이지 랭크 알고리즘
네이버 검색엔진의 문제점을 처음 지적한 글을 썼던 2년 전부터 이 블로그에 언젠가 한 번 써보고 싶었던 주제가 하나 있었다. 구글의 PageRank 알고리즘을 설명하는 것이다. 원리는 간단하지만 알고리즘을 설명하려고 하면 말이 길어질 것 같고 쉽게 설명할 수 있을까 싶어 블로그에 쓸까 말까 망설였는데, 그냥 한 번 시작해보려고 한다. “Google”이라는 230조원짜리 회사가 처음 시작된 곳이 바로 이 세르게이 브린과 래리 페이지가 쓴 논문(The Anatomy of a Large-Scale Hypertextual Web Search Engine)이었다는 것을 생각하면 한 번 시간을 들여 배워볼 만한 의미가 있지 않을까? 이 논문은 1998년에 쓰여졌으나, 논문에서 소개된 PageRank 알고리즘은 14년이 지난 지금에도 구글 검색 엔진의 핵심을 이루고 있다.
논문은 이렇게 시작한다.
Our main goal is to improve the quality of web search engines. In 1994, some people believed that a complete search index would make it possible to find anything easily. (우리의 주요 목표는 검색 엔진의 품질을 향상시키는 것입니다. 1994년 당시, 사람들은 검색 인덱스를 완성하고 나면 무엇이든 쉽게 찾을 수 있을 것이라고 생각했습니다.)
However, the Web of 1997 is quite different. Anyone who has used a search engine recently, can readily testify that the completeness of the index is not the only factor in the quality of search results. “Junk results” often wash out any results that a user is interested in. (하지만, 1997년의 웹은 사뭇 다릅니다. 최근에 검색 엔진을 사용해 본 사람이라면 누구나 인덱스를 완성하는 것만으로는 좋은 품질의 검색 결과를 얻을 수 없다는 것을 압니다. ‘쓰레기 정보’가 종종 사용자들이 진정 관심있어하는 정보를 가려버립니다.)
One of the main causes of this problem is that the number of documents in the indices has been increasing by many orders of magnitude, but the user’s ability to look at documents has not. People are still only willing to look at the first few tens of results. (그러한 이유 중 하나는, 인덱스되는 문서의 숫자는 엄청난 속도로 성장하고 있지만, 사람들이 그 문서들을 볼 수 있는 능력은 같은 속도로 성장하지 않기 때문입니다. 사람들은 여전히 검색 결과중 처음 몇십 개 정도만 살펴볼 뿐입니다.)
Because of this, as the collection size grows, we need tools that have very high precision. Indeed, we want our notion of “relevant” to only include the very best documents since there may be tens of thousands of slightly relevant documents. (그렇기 때문에, 인터넷이 성장할수록, 우리에게 더 정밀한 도구가 필요합니다. 사실, 우리는 ‘관련 있는 페이지’가 수만 개라도, 그 중 최고의 웹 페이지만을 정확하게 찾아주기를 원합니다.)
There is quite a bit of recent optimism that the use of more hypertextual information can help improve search and other applications. In particular, link structure and link text provide a lot of information for making relevance judgments and quality filtering. Google makes use of both link structure and anchor text. (하이퍼텍스트 정보를 이용하면 검색 결과를 많이 향상할 수 있다는 최근의 연구 결과가 있습니다. 특히, 웹 페이지 사이의 연결 관계가 상당히 유용한 정보를 제공해줄 수 있습니다. 구글은 바로 이러한 링크 구조와 링크 달린 텍스트를 이용합니다.)
그 알고리즘이 너무 매력적이었기에 그들은 구글을 세웠다
[권오성의 세상을 바꾼 데이터]검색 알고리즘 페이지랭크에 대한 이야기
페이지랭크. 출처: 위키미디어커먼스 Felipe Micaroni Lalli
인터넷은 그 자체가 데이터다. 물론 인터넷상에 수많은 글, 그림, 동영상 등이 컴퓨터 비트로 저장되어 있으니 당연한 소리라고 할 수도 있다. 말하고자 하는 바는 그런 콘텐츠가 아니라 보통 간과하는 인터넷의 구조, 즉 ‘링크’에 대한 이야기다. 링크에는 상상 이상의 정보가 담겨 있다.
오래전 여기에 주목한 한 청년이 있었다. 당시 사람들은 주로 분류나 추천에 따라 인터넷을 쓰고 있었다. 예컨대 뉴스를 보고 싶으면 ‘뉴스’라는 분류 페이지에 가서 , , 가운데 하나를 클릭해 읽는 식이었다. 검색도 그냥 글의 내용에 기반을 둬서 연관 있어 보이는 페이지를 권할 뿐이었다. 이 청년은 링크를 이용한다면 이런 정보 검색 방식을 혁신적으로 바꿔 놓을 수 있으리라고 생각했다.
수백만 개의 문서 가운데 가장 좋은 문서를 어떻게 찾을 수 있을까? 청년은 링크에 그 비밀이 있다고 생각했다. 설명을 위해 어떤 사람이 ‘문재인’을 검색했을 때 관련되는 모든 문서가 단지 4개뿐인 가상의 인터넷을 상상해 보자. 이 가운데 한 페이지가 문재인을 가장 잘 설명하는 페이지일 확률은 얼마일까? 다른 조건이 없다면 4개 모두 같을 테니 각각 1/4 확률을 가질 것이다.
페이지랭크 설명. 권오성.
이제 이 페이지들 사이에 위 그림처럼 링크가 걸려 있다고 하자. 즉, B, C, D 페이지가 A 페이지로 이동하는 링크를 걸고 있다. 청년은 이 경우 B, C, D가 A를 인정했다고 보고 자신의 확률(1/4)을 A에게 주는 것으로 해석했다. 이런 경우 확률 분포를 계산하면 A의 확률은 1이 되고 나머지는 0이 된다. 따라서 이 가상의 인터넷에서 가장 좋은 문서는 A가 된다.
페이지랭크 설명. 권오성.
이제 링크들이 위 그림처럼 걸려 있다고 하자. B, C, D는 여전히 A로 향하는 링크를 걸고 있지만, 동시에 A도 B로 향하는 링크를 걸고 있고, C는 A뿐 아니라 D로 향하는 링크도 있다고 한다. 이때 확률은 어떻게 배분되어야 하는가. 앞과 같은 식으로 계산해 보자. A, B, C, D가 모두 같은 확률(1/4)로 시작한다고 했을 때, A는 B를 향하는 링크만 있으니 자신의 확률을 모두 B에 준다. B는 역시 A를 향하고 있으므로 1/4을 양도한다. C는 A와 D 두 곳을 향하고 있다. 이럴 경우 자신의 확률을 똑같이 나누어 준다. 즉, A와 D에게 각각 1/8을 주는 것이다. D는 역시 A를 향하고 있으므로 1/4을 양도한다. 이렇게 배분을 하고 나면 각각 확률은 A=5/8, B=1/4, C=0, D=1/8이 되는 것이다.
그런데 이러면 각 페이지가 가지고 있는 확률이 달라짐을 알 수 있다. 그러면 다시 계산을 해봐야 하지 않을까? 즉 A는 자신의 확률(5/8)을 B에게 주고, B도 주고(1/4), C, D도 다시 배분하는 것이다. 그러면 새 값이 나오고 또 다시 계산해야 한다. 청년은 이런 과정이 계속 반복되면 각 문서에 얼마의 확률이 배정되는지에 대한 수학적인 방법을 고안했다. 그 값이 해당 문서의 가치가 되는 셈이다.
이 청년의 이름은 래리 페이지(Larry Page)이고, 이 알고리즘이 바로 ‘페이지랭크’(Pagerank)이다. 래리 페이지는 이런 이론이 실제 그럴싸한 결과를 내놓는지 알고 싶었다. 그가 검증을 위해 다니던 미국 스탠퍼드 대학교 컴퓨터 학과의 한 학년 위 동료이자 수학 천재로 불렸던 세르게이 브린(Sergey Brin)과 함께 세운 회사가 바로 ‘구글’인 것이다. 구글은 이 기본 방법론을 수억, 수십억 개의 웹페이지로 확장해서 구현한 결과일 뿐이다. 그 검증의 결과가 어떻게 되는지는 우리 모두 알고 있다. 구글의 검색엔진 알고리즘은 이후 굉장히 복잡하게 진화했지만 그 기본은 여전히 페이지랭크다.
1996년 탄생한 페이지랭크 알고리즘은 사실 많은 선배들의 어깨를 딛고 선 결과이다. 모든 문서가 다른 문서와 링크로 연결된 구조는 우연히 나온 게 아니라 ‘월드와이드웹(WWW)의 아버지’로 불리는 팀 버너스-리(Tim Berners-Lee)가 1989년 하이퍼텍스트(HTML)를 고안하며 정확히 의도한 바다. 그는 세상의 모든 정보를 이렇게 연결하는 것이 인류의 지식에 큰 이로움을 가져오리라 생각했다. 는 구글이 “버너스-리의 월드와이드웹에 대한 역공학(reverse engineer)의 산물”이라고 평했다. 버너스-리의 하이퍼텍스트는 학계가 오랜 동안 발전시킨 학술 인용(citation) 방법론에서 연유한다. 또 페이지랭크의 통계적 방법론은 안드레이 마르코프(Andrey Markov) 같은 19세기 통계학자들이 없었으면 불가능한 일이다. 마르코프 역시 그 선배 수학자들에 빚지고 있다.
구글의 현재 시가총액은 8200억 달러(약 979조원)가 넘는다. 하지만 그 고갱이는 최적의 정보를 찾는 하나의 방법론에 대한 검증이었다. ‘4차 산업혁명’이라는 결과에 열광하는 시대에 그 원인을 보는 눈이 더 필요하지 않은가 싶다.
권오성 기자 [email protected]
So you have finished reading the 페이지 랭크 topic article, if you find this article useful, please share it. Thank you very much. See more: 페이지랭크 나무위키, 페이지랭크 마르코프, Personalized PageRank 설명, PageRank 설명, 구글행렬, Networkx PageRank, 구글 랭킹 알고리즘, 래리페이지