
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 정규화 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://toplist.maxfit.vn team, along with other related topics such as: 정규화 정규화 공식, 정규화 뜻, 데이터 정규화, 수학 정규화, 정규화 표준화, DB 정규화, SQL 정규화, 통계 정규화
데이터베이스 정규화 – 위키백과, 우리 모두의 백과사전
- Article author: ko.wikipedia.org
- Reviews from users: 42353
 Ratings
Ratings - Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about 데이터베이스 정규화 – 위키백과, 우리 모두의 백과사전 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다. 데이터베이스 정규화의 목표는 이상이 있는 … …
- Most searched keywords: Whether you are looking for 데이터베이스 정규화 – 위키백과, 우리 모두의 백과사전 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다. 데이터베이스 정규화의 목표는 이상이 있는 …
- Table of Contents:
정규화의 목적[편집]
배경 지식 정의[편집]
인용 자료[편집]
외부 링크[편집]
![]()
[DB] 정규화(Normalization)란? 정규화 예시, 1NF, 2NF, 3NF, BCNF
- Article author: code-lab1.tistory.com
- Reviews from users: 6705 Ratings
- Top rated: 3.1
- Lowest rated: 1
- Summary of article content: Articles about [DB] 정규화(Normalization)란? 정규화 예시, 1NF, 2NF, 3NF, BCNF 정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다. 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성 … …
- Most searched keywords: Whether you are looking for [DB] 정규화(Normalization)란? 정규화 예시, 1NF, 2NF, 3NF, BCNF 정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다. 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성 … 정규화(Normalization)란? 정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다. 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성하게 된다. 이를 단계별로 구분하여..
- Table of Contents:
Header Menu
Main Menu
[DB] 정규화(Normalization)란 정규화 예시 1NF 2NF 3NF BCNF‘Computer Science[DB]’ 관련 글
Sidebar – Right
Copyright © 코드 연구소 All Rights Reserved
Designed by JB FACTORY
티스토리툴바
![[DB] 정규화(Normalization)란? 정규화 예시, 1NF, 2NF, 3NF, BCNF](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FpwqKp%2Fbtrj2WEouSq%2FrHLj2INEMyM1PkzYkWATK1%2Fimg.png)
[Database] 정규화(Normalization) 쉽게 이해하기 – MangKyu’s Diary
- Article author: mangkyu.tistory.com
- Reviews from users: 4578 Ratings
- Top rated: 4.9
- Lowest rated: 1
- Summary of article content: Articles about [Database] 정규화(Normalization) 쉽게 이해하기 – MangKyu’s Diary 정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity) … …
- Most searched keywords: Whether you are looking for [Database] 정규화(Normalization) 쉽게 이해하기 – MangKyu’s Diary 정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity) … 지난 포스팅에서 데이터베이스 정규화와 관련된 내용을 정리했었다. 하지만 해당 내용이 쉽게 이해되지 않는 것 같아서 정규화 관련 글을 풀어서 다시 한번 정리해보고자 한다. 1. 정규화(Normalization) [ 정규화..
- Table of Contents:
티스토리 뷰
1 정규화(Normalization)
티스토리툴바
![[Database] 정규화(Normalization) 쉽게 이해하기 - MangKyu's Diary](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbNbQUm%2FbtqT18yag04%2FpTXJX3wB23ouk8az7EgWQ1%2Fimg.png)
데이터베이스 정규화(Normalization)란 :: AndroidTeacher
- Article author: hongcoding.tistory.com
- Reviews from users: 5348 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about 데이터베이스 정규화(Normalization)란 :: AndroidTeacher 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다. 정규화의 기본 목표는 관련이 없는 함수 종속성은 … …
- Most searched keywords: Whether you are looking for 데이터베이스 정규화(Normalization)란 :: AndroidTeacher 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다. 정규화의 기본 목표는 관련이 없는 함수 종속성은 … 데이터베이스 정규화(Normalization) 란? 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다. 정규화의 기본 목표는 관련이 없는 함수 종속성은 별개의 릴레이션..
- Table of Contents:
데이터베이스 정규화(Normalization)란
티스토리툴바
데이터베이스 정규화 – IT위키
- Article author: itwiki.kr
- Reviews from users: 40819 Ratings
- Top rated: 4.3
- Lowest rated: 1
- Summary of article content: Articles about 데이터베이스 정규화 – IT위키 정규화를 거치지 않은 데이터베이스에서 발생할 수 있는 현상; 데이터들이 불필요하게 중복되어 릴레이션 조작에 예기치 못한 문제 발생 … …
- Most searched keywords: Whether you are looking for 데이터베이스 정규화 – IT위키 정규화를 거치지 않은 데이터베이스에서 발생할 수 있는 현상; 데이터들이 불필요하게 중복되어 릴레이션 조작에 예기치 못한 문제 발생 …
- Table of Contents:
익명 사용자
목차
이상(Anomaly) 현상[편집 원본 편집]
정규화 목적[편집 원본 편집]
정규화 과정[편집 원본 편집]
둘러보기
위키 도구
문서 도구
분류 목록

[데이터베이스]정규화(Normalization)
- Article author: velog.io
- Reviews from users: 30593 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about [데이터베이스]정규화(Normalization) 정규화(Normalization). 데이터들을 최대한 중복을 제거하여 이상 현상 ( Anomaly ) 을 방지하기 위한 기술. 중복된 데이터를 허용하지 않음으로써 … …
- Most searched keywords: Whether you are looking for [데이터베이스]정규화(Normalization) 정규화(Normalization). 데이터들을 최대한 중복을 제거하여 이상 현상 ( Anomaly ) 을 방지하기 위한 기술. 중복된 데이터를 허용하지 않음으로써 … 데이터들을 최대한 중복을 제거하여 이상 현상 ( Anomaly ) 을 방지하기 위한 기술중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.갱신 이상 ( Modification Anomaly )중복된
- Table of Contents:
데이터베이스
이상 현상
정규화 과정
제 1 정규화
제 2정규화
제 3정규화
BCNF 정규화
![[데이터베이스]정규화(Normalization)](https://velog.velcdn.com/images/jihun333/post/38a55c5d-2bdd-4ba9-b448-cffdccb6c80f/image.png)
[통계] 정규화(Normalization) vs 표준화(Standardization)
- Article author: heeya-stupidbutstudying.tistory.com
- Reviews from users: 23266 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about [통계] 정규화(Normalization) vs 표준화(Standardization) 정규화의 목적은 데이터셋의 numerical value 범위의 차이를 왜곡하지 않고 공통 척도로 변경하는 것이다. 기계학습에서 모든 데이터셋이 정규화 될 … …
- Most searched keywords: Whether you are looking for [통계] 정규화(Normalization) vs 표준화(Standardization) 정규화의 목적은 데이터셋의 numerical value 범위의 차이를 왜곡하지 않고 공통 척도로 변경하는 것이다. 기계학습에서 모든 데이터셋이 정규화 될 … ML을 공부하는 사람이라면 feature scaling이 얼마나 중요한 지 알것이다. scikit-learn에는 많은 스케일링 메서드들이 모듈화 되어있는데, 기본적으로 정규화와 표준화가 무엇인지 이해해야 과제를 수행하기 적합..
- Table of Contents:
정규화 (Normalization)
태그
‘AIStatistics’ 관련글
Comments
티스토리툴바
![[통계] 정규화(Normalization) vs 표준화(Standardization)](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbuFiP1%2FbtrfoRhJjrp%2Frpu2mJTNe2fLxsQ13MuYBk%2Fimg.webp)
ì측 모ë¸ë§ì ì ê·í ë° ë³´ê° – Tableau
- Article author: help.tableau.com
- Reviews from users: 45372 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about ì측 모ë¸ë§ì ì ê·í ë° ë³´ê° – Tableau 정규화 및 보강과 함께 작동하는 모델은 무엇입니까? Tableau의 예측 모델링 함수는 선형 회귀(최소 자승 회귀 또는 OLS라고도 함), 정규화된 선형 회귀(또는 리지 회귀) … …
- Most searched keywords: Whether you are looking for ì측 모ë¸ë§ì ì ê·í ë° ë³´ê° – Tableau 정규화 및 보강과 함께 작동하는 모델은 무엇입니까? Tableau의 예측 모델링 함수는 선형 회귀(최소 자승 회귀 또는 OLS라고도 함), 정규화된 선형 회귀(또는 리지 회귀) …
- Table of Contents:
ì ê·í ë° ë³´ê°ê³¼ í¨ê» ìëíë 모ë¸ì 무ìì ëê¹
ì ê·íë
ë³´ê°ì´ë
ê³ì°ìì ëë¤ ë° ë³´ê° êµ¬ì±
ì ê·í ë° ë³´ê°ì ëí ê³ ë ¤ ì¬í
See more articles in the same category here: toplist.maxfit.vn/blog.
위키백과, 우리 모두의 백과사전
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다. 데이터베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것에 있다. 일반적으로 정규화란 크고, 제대로 조직되지 않은 테이블들과 관계들을 작고 잘 조직된 테이블과 관계들로 나누는 것을 포함한다. 정규화의 목적은 하나의 테이블에서의 데이터의 삽입, 삭제, 변경이 정의된 관계들로 인하여 데이터베이스의 나머지 부분들로 전파되게 하는 것이다.
관계형 모델의 발견자인 에드거 F. 커드는 1970년에 제 1 정규화(1NF)로 알려진 정규화의 개념을 도입하였다.[1] 에드거 F. 커드는 이어서 제 2 정규화(2NF)와 제 3 정규화(3NF)를 1971년에 정의하였으며,[2] 1974년에는 레이먼드 F. 보이스와 함께 보이스-코드 정규화(BCNF)를 정의하였다.[3] 4NF 이상의 정규화는 이후에 다른 이론가들에 의해서 정의되었으며, 가장 최근에 소개된 정규화는 2002년에 크리스토퍼 J. 데이트, 허그 다위, 니코스 로렌츠에 의해 소개된 제 6 정규화(6NF)이다.
비공식적으로 관계형 데이터베이스 테이블(컴퓨터 공학적 표현으로는 관계)이 제 3 정규(3NF)화가 되었으면 정규화되었다라고 한다. 3NF 테이블의 대부분이 삽입, 변경, 삭제 이상이 없으며, 3NF 테이블의 대부분이 BCNF, 4NF, 5NF이다.(그러나 일반적으로 6NF는 아니다.)
데이터베이스 디자인 표준 가이드는 데이터베이스가 완전히 정규화되게 디자인되어야 한다; 그 뒤에 일부가 성능상의 이유로 비정규화될 수는 있다. 그러나, 데이터 웨어하우스 디자인을 위한 관점 모델링과 같은 일부 모델링 규칙에서는 예외적으로 비 정규화된 디자인을 추천한다. 즉 대규모 부분에서의 디자인은 3NF가 아니다.[7]
정규화의 목적 [ 편집 ]
1970년 에드거 F. 커드에 의해 정의된 제 1 정규형의 기본적의 목적은 1차 논리에 기반을 둔 “보편적 데이터 부언어”에 의해 데이터가 질의되고 조작되게 하기 위해서였다.[8] (SQL이 이 데이터 부언어의 대표적인 예이지만, 정작 에드거 F. 커드는 이 언어는 심각한 결함을 가지고 있다고 생각하였다.)[9]
에드거 F. 커드에 의해 정의된 제 1 정규화(1NF)의 목적은 아래와 같다.
1. 고려되지 않은 삽입, 갱신, 삭제 의존에서부터 관계의 집합을 배제한다. 2. 새로운 자료형이 나타날 때, 관계들의 집합의 재구성의 필요성을 낮추고, 그로 인하여 응용 프로그램의 생명주기를 연장한다. 3. 사용자에게 관계 모델을 더욱 의미있게 한다. 4. 관계들의 집합을 질의의 통계로부터 중립적이게 한다. 질의들은 시간이 지남에 따라 변경되기 때문이디. —E.F. Codd, “Further Normalization of the Data Base Relational Model”[10]
이 목적들을 아래에서 더욱 자세히 알아본다.
데이터베이스의 변경시 이상 현상 제거 [ 편집 ]
갱신 이상. Employee 519는 다른 레코드에서 다른 주소를 가지고 있다. . Employee 519는 다른 레코드에서 다른 주소를 가지고 있다.
삽입 이상. 신입 교수인 Dr. Newsome은 아직 수업을 배정받지 않았다는 이유로 교수 정보를 관리하는 이 테이블에 Newsome 교수 레코드를 삽입할 수가 없다. . 신입 교수인 Dr. Newsome은 아직 수업을 배정받지 않았다는 이유로 교수 정보를 관리하는 이 테이블에 Newsome 교수 레코드를 삽입할 수가 없다.
삭제 이상. ENG-206 수업이 끝나 해당 레코드를 삭제하면, Dr. Giddens 교수의 모든 정보가 삭제된다. . ENG-206 수업이 끝나 해당 레코드를 삭제하면, Dr. Giddens 교수의 모든 정보가 삭제된다.
테이블 수정(갱신, 삽입, 삭제)시, 원치 않던 부작용이 발생할 수 있다. 이 부작용은 충분히 정규화되지 않은 테이블에서 발생할 수 있는데, 충분히 정규화 되지 않은 테이블은 아래와 같은 특성들이 있다:
같아야 하는 정보가 복수 개의 행에서 표현되면, 갱신 시 논리적인 모순을 초래할 수 있다. 예를 들어, "직원 보유기술”이라는 테이블에서 모든 레코드가 직원 ID, 직원 보유기술, 직원 주소를 포함하고 있다고 하면, 특정 직원의 주소 변경 시 여러 개의 레코드를 함께 수정해야 한다(그 직원이 보유한 모든 보유기술에 대해 레코드가 수정되어야 한다). 성공적인 갱신이 이루어지지 않을 경우-즉, 변경된 직원의 주소가 그가 가지고 있는 레코드 중에서 일부는 변경되었으나, 일부는 변경되지 않을 경우- “직원 보유기술” 테이블은 모순 상태가 된다. 즉, 그 특정 직원의 주소가 무엇인가에 대한 질문에 대해서 혼동스러운 답안을 내놓게 된다. 이런 현상을 갱신 이상이라고 한다.
“교수와 그들의 강의”라는 테이블에서 교수 ID, 교수 이름, 교수 임용일자, 수업 코드를 가지고 있다고 하자. 새 교수를 임용하였을 경우, 그가 맡은 강의가 없으면 수업 코드가 널(빈값)이어서 수업 코드가 식별컬럼(널 비허용)인 이 테이블에 추가할 수가 없게 되는데, 이런 현상을 삽입 이상이라고 한다.
어떤 정보를 삭제하는데, 삭제되면 안 되는 다른 사실이 함께 삭제되는 현상이 있을 수 있다. 예를 들어, “교수와 그들의 강의”라는 위 예제에서 Dr. Griddens 교수가 ENG-206 수업을 임시로 중단하고자 하면, 이런 이상현상이 발생한다. 다시 말해 그가 맡은 수업 정보가 기록된 레코드들을 삭제하는 경우, 교수 정보 전체가 사라지게 되는데, 이런 현상을 삭제 이상이라고 한다.
데이터베이스 구조 확장시 재 디자인 최소화 [ 편집 ]
정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 되는 경우가 있다. 이는 이 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 주며, 응용 프로그램의 생명을 연장시킨다.
사용자에게 데이터 모델을 더욱 의미있게 [ 편집 ]
정규화된 테이블들과 정규화된 테이블들간의 관계들은 현실세계에서의 개념들과 그들간의 관계들을 반영한다. 즉 데이터 모델을 사용자에게 더욱 의미(informative)있게 한다.
다양한 질의 지원 [ 편집 ]
정규화된 테이블은 일반적인 목적의 질의에 적합하다. 이는 테이블에 대하여 세부사항이 예측되지 않은 장래의 질의를 포함한 어떠한 질의도 지원한다는 의미이다. 반대로 정규화되지 않은 테이블은 (향후 발생할 수 있는) 어떤 질의들은 지원하지 않을 수 있다.
예를 들어서, 고객이 가지고 싶은 책들의 목록을 가지고 있는 온라인 서점을 생각해보자. 분명하게 예상되는 질의 — 고객이 원하는 책은 무엇인가? –는 고객이 가지고 싶은 책들의 목록 테이블에 저자와 제목이 있으면 된다.
이 테이블 디자인은 그 한 질의에 대해서는 답할 수 있다. 그러나 다른 예상되거나 관심있는 질의들은 답할 수 없다: 고객들이 가장 선호하는 책은? 어떤 고객들이 2차 세계대전 스파이들에 대해서 관심있는가? 이 질의에 대한 답을 구하기 위해서는 데이터베이스와 완전히 분리되어 이 질의를 다루는 소프트웨어를 구현하여야 하며, 이 소프트웨어의 목표는 한가지이다: 비 정규화된 항목을 정규화한다.
정규화된 테이블에서는 예측되지 않는 질의라고 하여도 순전히 데이터베이스의 테두리 안에서 쉽게 답변이 가능하다.
예제 [ 편집 ]
고객들의 신용카드 사용 내역을 표현한 테이블을 가정하자. 이 테이블이 제 1 정규화가 안 되었을 경우, 데이터의 질의와 조작은 필요 이상으로 복잡해진다:
고객 사용내역 홍길동 거래번호 일자 잔고 12890 2010-10-14 −87 12904 2010-10-15 −50 최철수 거래번호 일자 잔고 12898 2010-10-14 −21 한영미 거래번호 일자 잔고 12907 2010-10-15 −18 14920 2010-11-20 −70 15003 2010-11-27 −60
각 고객들마다, 거래의 반복이 있다. 그래서 고객의 거래에 대한 질의에 답하기 위해서는 아래의 2단계가 필요하다:
각 거래들을 조사하기 위해서 하나 이상의 고객들의 거래들의 모임으로부터 각 거래를 추출하여 그룹화 위 첫 단계의 결과로부터 질의의 결과를 도출
예를 들어서, 모든 고객들에 대하여 2010년 10월에 이루어진 모든 거래의 거래량(돈)의 합을 구하기 위해서는 :
각 고객들로부터 고객들의 거래의 모임을 각 거래들로 추출 일자가 2010년 10월인 거래들의 잔고의 합을 구한다.
에드거 F. 커드는 이러한 데이터 구조의 복잡성이 완전히 제거되었을 때 질의가 (사용자와 응용 프로그램에 의해서)표현되고 (DBMS에 의해서) 수행됨에 있어서 더욱 강력하고 유연해진다고 보았다. 위 구조를 정규화하면 아래와 같다:
고객 거래번호 일자 잔고 홍길동 12890 2010-10-14 −87 홍길동 12904 2010-10-15 −50 최철수 12898 2010-10-14 −21 한영미 12907 2010-10-15 −18 한영미 14920 2010-11-20 −70 한영미 15003 2010-11-27 −60
이제 각 행은 각 신용카드 거래를 의미하며, DBMS는 위 질의에 대해서 2010년 10월에 해당하는 모든 행을 구해서 그들의 잔고를 합하면 된다. 이 데이터 구조는 모든 값이 동등한 입장을 가지며, DBMS에 직접적으로 반영되어 질의에 잠재적으로 참여할 수 있게 된다; 이전의 상황에서는 각 값이 하위 레벨 구조로 묶여서 질의시 따로 취급되어야 했다. 이런 이유로 정규화된 디자인은 일반적인 목적의 질의에 적합하며, 비정규화된 디자인은 그렇지 않다.
배경 지식 : 정의 [ 편집 ]
함수 종속성 관계 스키마 중에서 어느 속성군의 값이 정해지면 다른 속성군의 값이 정해지는 것. A, B가 각각 관계 R의 속성인 경우, 임의 시점에서 A의 어떤 값도 반드시 B의 하나의 값에 대응되지만, B의 하나의 값이 A의 복수의 값에 대응되는 경우에 B는 A에 함수 종속이라고 하며 A→B와 같이 표기한다. 예를 들어, “직원” 테이블이 “직원 ID” 속성과 “직원 생일” 속성을 가질 때, {직원 ID}->{직원 생일} 또는 {직원 생일}은 {직원 ID}에 함수 종속이다. 실제로는 {직원 생일}이 null 이거나 어떤 {직원 생일}에도 대응되지 않을 수 있으므로 맞지 않을 수도 있으나, 여기에서는 {직원 ID}는 정확히 하나의 {직원 생일}만 갖는다고 가정한다. 자명한 함수 종속성 속성들의 부분집합이 함수 종속성을 가질때, 자명한 함수 종속성(FD)이라고 한다. {직원 ID}->{직원 생일} 이면 {직원 ID, 직원 주소}->{직원 생일} 은 자명하다. 완전함수 종속성 A, B가 각각 관계 R의 속성이고 B가 A에 함수 종속(A→B)인 경우, A의 임의의 부분 집합에 대하여 B의 어떤 값도 A의 부분 집합의 값에 대응하지 않으면 B는 A에 완전함수(적) 종속이라고 한다. 이행함수 종속성 A, B, C가 각각 관계 R에 상호 중복되지 않는 속성(다만, A는 1차 키 이외의 속성)인 경우에, A가 B에 함수 종속적이 아니면 이때 C는 A에 이행함수 종속이라고 한다. 제2정규형(2NF)의 관계에 이행함수 종속성이 있는 경우, 그것을 배제하고 분해한 관계를 제3정규형(3NF)이라고 한다. A->B 이고 B->C 일 경우에만 A->C 이면 이행함수(적) 종속이라고 한다. 다치 종속성 다치 종속성(MVD)은 어떤 레코드의 존재가 다른 레코드의 존재로 이어짐을 의미한다. 다치종속성은->>으로 표시하는데, R{A,B,C}일 때 (A,C)->>{B}≡(A) ->{B} 성립한다. , A->>B이면 A->>C도 성립하고 A->>B│C이다. (Fagin정리에 따라) R{A,B,C}에서 다치종속 A->>B│C이면 R1{A,B}와 R2{A,C}로 무손실 분해가 가능하다. 이를 제4정규형(4NF)의 관계에 있다고 말한다. 조인 종속 조인종속(JD)는 릴레이션 R이 그의 프로젝션 A,B,…..,Z의 조인과 동일하면 R은 JD*(A,B,….,Z )를 만족한다. 이때 A,B,….,Z는 R의 애트리뷰트에 대한 부분집합이다. 다시말해서 테이블 R이 R의 속성의 부분집합을 가지는 여러 개의 테이블들을 조인하여 만들어질 수 있을 때, R은 조인 종속성을 가진다고 한다. 이를 제5정규형(5NF)이라고 한다.
슈퍼 키 슈퍼키는 레코드를 유일하게 식별해낼 수 있는 속성들의 집합이다. 한 개의 테이블은 여러 개의 슈퍼키를 가질 수 있다. 후보 키 후보 키는 슈퍼 키에서 레코드를 유일하게 식별하는데 있어서 필요없는 속성을 제거한 슈퍼 키의 부분집합이다.
예제 : {이름},{나이},{주민등록 번호},{전화번호} 속성을 가지는 테이블에서 슈퍼키는 {주민등록 번호}, {전화번호, 이름}, {주민등록 번호, 이름} 3개이다. 이들중 {주민등록 번호}가 후보 키이며, 나머지 속성들은 레코드를 유일하게 식별하는데 있어서는 필요없는 속성들이다.
비일차 속성 비일차 속성은 어떤 후보 키에도 나타나지 않는 속성이다. {이름},{나이},{주민등록 번호},{전화번호} 속성을 가지는 테이블에서 {나이}는 비일차 속성이다. 일차키 관계 데이터베이스(RDB)에서 관계(데이터베이스 테이블) 내의 특정 투플(열)을 일의적으로 식별할 수 있는 키 필드. 주 키(major key)라고도 한다. 파일에서 특정 레코드를 검색하거나 레코드들을 정렬할 때 우선적으로 참조된다. 관계 내의 키 필드가 하나밖에 없을 때에는 자동적으로 그 관계의 일차 키가 된다. 그러나 하나의 관계 내에 복수의 키가 있을 때에는 그중의 하나를 일차 키로 지정해야 한다. 일차 키로 지정되지 않은 키를 대체 키(alternate key)라고 한다.
인용 자료 [ 편집 ]
Paper: “Non First Normal Form Relations” by G. Jaeschke, H. -J Schek ; IBM Heidelberg Scientific Center. -> Paper studying normalization and denormalization operators nest and unnest as mildly described at the end of this wiki page.
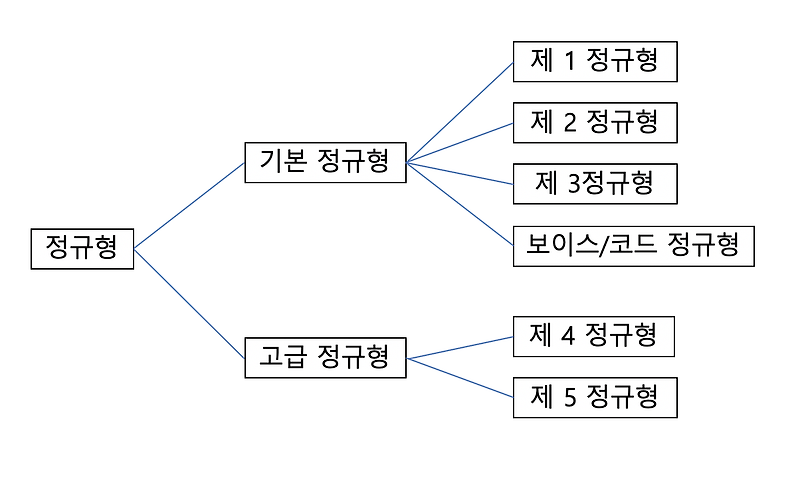
[DB] 정규화(Normalization)란? 정규화 예시, 1NF, 2NF, 3NF, BCNF
정규화(Normalization)란?
정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다. 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성하게 된다. 이를 단계별로 구분하여 정규형이 높아질수록 이상현상은 줄어들게 된다.
정규화의 장점
데이터베이스 변경 시 이상 현상(Anomaly)을 제거할 수 있다.
정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 되어 응용프로그램의 생명을 연장시킨다.
정규화의 단점
릴레이션의 분해로 인해 릴레이션 간의 JOIN연산이 많아진다.
질의에 대한 응답시간이 느려질 수도 있다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
있다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다. 따라서 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있다.
만약 조인이 많이 발생하여 성능저하가 나타나면 반정규화(De-normalization)를 적용할 수도 있다.
정규화를 알아보기 전에, 이상현상과 함수 종속성에 대해서 꼭 알아야 한다. 아래 포스팅을 참고하자.
제 1정규형 (1NF)
제 1정규형은 다음과 같은 규칙들을 만족해야 한다.
1. 각 컬럼이 하나의 속성만을 가져야 한다.
2. 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다.
3. 각 컬럼이 유일한(unique) 이름을 가져야 한다.
4. 칼럼의 순서가 상관없어야 한다.
조금 복잡해보이지만, 간단하게 예시를 들면 이해가 빠르다. 아래 테이블을 살펴보자.
1정규화가 필요한 테이블
각 컬럼이 하나의 값(속성)만을 가져야 한다. -> 불만족! 하나의 컬럼(과목)에 두 개의 값을 가짐 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다. -> 만족 각 컬럼이 유일한(unique) 이름을 가져야 한다. -> 만족 칼럼의 순서가 상관없어야 한다. -> 만족
1번 규칙을 불만족하므로 이를 고치기 위해서는 아래와 같이 분해하면 된다.
1NF
위와 같이 각 컬럼이 원자 값을 갖도록 테이블을 분해하면 1정규형을 만족하게 바꿀 수 있다.
제 2정규형 (2NF)
제 2정규형은 다음과 같은 규칙을 만족해야 한다.
1. 1정규형을 만족해야 한다.
2. 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. == 모든 컬럼이 완전 함수 종속을 만족해야 한다.
부분적 종속이란 기본키 중에 특정 컬럼에만 종속되는 것이다.
완전 함수 종속이란 기본키의 부분집합이 결정자가 되어선 안된다는 것이다. ( 비슷한 말이다 )
2정규화가 필요한 테이블
위와 같은 테이블과 FD 다이어그램을 보자.
성적의 특정 값을 알기 위해서는 학생 번호+과목이 있어야 한다. (ex : 102번의 자바 성적 70 )
하지만 특정 과목의 지도교수는 과목명만 알면 지도교수가 누군지 알 수 있다. (ex : 자바의 지도교수 박자바)
위 테이블에서 기본키는 (학생 번호, 과목)으로 복합키이다.
그런데 이때 지도교수 칼럼은 (학생번호, 과목)에 종속되지 않고 (과목) 에만 종속되는 부분적 종속이다.
따라서 제 2정규화를 만족하지 않으므로 아래와 같이 분해해야 한다.
2NF
위와 같이 분해하면 제 2정규형을 만족한다.
제 3정규형 (3NF)
제 3정규형은 다음과 같은 규칙을 만족해야 한다.
1. 2정규형을 만족해야 한다.
2. 기본키를 제외한 속성들간의 이행 종속성 (Transitive Dependency)이 없어야 한다.
이행 종속성이란 A->B, B->C 일 때 A->C 가 성립하면 이행 종속이라고 한다.
3정규화가 필요한 테이블
위와 같은 테이블을 보자. ID를 알면 등급을 알 수 있다. 등급을 알면 할인율을 알 수 있다. 따라서 ID를 알면 할인율을 알 수 있다. 따라서 이행 종속성이 존재하므로 제 3정규형을 만족하지 않는다.
3정규형을 만족하기 위해서는 아래와 같이 분해해야 한다.
3NF
위와 같이 분해하면 제 3정규형을 만족한다.
BCNF (Boyce-Codd Normal Form)
BCNF는 제 3정규형을 좀 더 강화한 버전으로 다음과 같은 규칙을 만족해야 한다.
1. 3정규형을 만족해야 한다.
2. 모든 결정자가 후보키 집합에 속해야 한다.
모든 결정자가 후보키 집합에 속해야 한다는 뜻은, 후보키 집합에 없는 컬럼이 결정자가 되어서는 안된다는 뜻이다.
BCNF가 필요한 테이블
위와 같은 테이블을 보자. (학생번호, 과목)이 기본키로 지도교수를 알 수 있다. 하지만 같은 과목을 다른 교수가 가르칠 수도 있어서 과목->지도교수 종속은 성립하지 않는다. 하지만 지도교수가 어떤 과목을 가르치는지는 알 수 있으므로
지도교수->과목 종속이 성립한다.
이처럼 후보키 집합이 아닌 컬럼이 결정자가 되어버린 상황을 BCNF를 만족하지 않는다고 한다.
(참고로 위 테이블은 제 3정규형까지는 만족하는 테이블이다 )
BCNF를 만족하기 위해서는 아래와 같이 분해하면 된다.
BCNF
4정규형 이상~
정규형
보통 정규화는 BCNF 까지만 하는 경우가 많다. 그 이상 정규화를 하면 정규화의 단점이 나타날 수도 있다.
4정규형 이상은 다음에 알아보도록 하자.
반응형
[Database] 정규화(Normalization) 쉽게 이해하기
반응형
지난 포스팅에서 데이터베이스 정규화와 관련된 내용을 정리했었다. 하지만 해당 내용이 쉽게 이해되지 않는 것 같아서 정규화 관련 글을 풀어서 다시 한번 정리해보고자 한다.
1. 정규화(Normalization)
[ 정규화(Normalization)이란? ]정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
이러한 테이블을 분해하는 정규화 단계가 정의되어 있는데, 여기서 테이블을 어떻게 분해되는지에 따라 정규화 단계가 달라지는데, 각각의 정규화 단계에 대해 자세히 알아보도록 하자.
[ 제1 정규화 ]제1 정규화란 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것이다. 예를 들어 아래와 같은 고객 취미 테이블이 존재한다고 하자.
위의 테이블에서 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제1 정규형을 만족하지 못하고 있다. 그렇기 때문에 이를 제1 정규화하여 분해할 수 있다. 제1 정규화를 진행한 테이블은 아래와 같다.
[ 제2 정규화 ]제2 정규화란 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다. 여기서 완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다.
예를 들어 아래와 같은 수강 강좌 테이블을 살펴보자.
이 테이블에서 기본키는 (학생번호, 강좌이름)으로 복합키이다. 그리고 (학생번호, 강좌이름)인 기본키는 성적을 결정하고 있다. (학생번호, 강좌이름) –> (성적)
그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌이름에 의해 결정될 수 있다. (강좌이름) –> (강의실)
즉, 기본키(학생번호, 강좌이름)의 부분키인 강좌이름이 결정자이기 때문에 위의 테이블의 경우 다음과 같이 기존의 테이블에서 강의실을 분해하여 별도의 테이블로 관리하여 제2 정규형을 만족시킬 수 있다.
[ 제3 정규화 ]제3 정규화란 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다. 여기서 이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것을 의미한다.
예를 들어 아래와 같은 계절 학기 테이블을 살펴보자.
기존의 테이블에서 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다. 그렇기 때문에 이를 (학생 번호, 강좌 이름) 테이블과 (강좌 이름, 수강료) 테이블로 분해해야 한다.
이행적 종속을 제거하는 이유는 비교적 간단하다. 예를 들어 501번 학생이 수강하는 강좌가 스포츠경영학으로 변경되었다고 하자. 이행적 종속이 존재한다면 501번의 학생은 스포츠경영학이라는 수업을 20000원이라는 수강료로 듣게 된다. 물론 강좌 이름에 맞게 수강료를 다시 변경할 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 하는 것이다.
즉, 학생 번호를 통해 강좌 이름을 참조하고, 강좌 이름으로 수강료를 참조하도록 테이블을 분해해야 하며 그 결과는 다음의 그림과 같다.
[ BCNF 정규화 ]BCNF 정규화란 제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것이다. 예를 들어 다음과 같은 특강수강 테이블이 존재한다고 하자.
특강수강 테이블에서 기본키는 (학생번호, 특강이름)이다. 그리고 기본키 (학생번호, 특강이름)는 교수를 결정하고 있다. 또한 여기서 교수는 특강이름을 결정하고 있다.
그런데 문제는 교수가 특강이름을 결정하는 결정자이지만, 후보키가 아니라는 점이다. 그렇기 때문에 BCNF 정규화를 만족시키기 위해서 위의 테이블을 분해해야 하는데, 다음과 같이 특강신청 테이블과 특강교수 테이블로 분해할 수 있다.
반응형
So you have finished reading the 정규화 topic article, if you find this article useful, please share it. Thank you very much. See more: 정규화 공식, 정규화 뜻, 데이터 정규화, 수학 정규화, 정규화 표준화, DB 정규화, SQL 정규화, 통계 정규화