
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 엔티티 테이블 차이 on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://toplist.maxfit.vn team, along with other related topics such as: 엔티티 테이블 차이 데이터베이스 테이블, JPA @Entity create table, DB 엔티티 란, 엔티티정의서, JPA table schema, JPA view 테이블, JPA 다른 스키마, 데이터베이스 용어
We.TIL 36 : 엔티티와 테이블의 차이
- Article author: velog.io
- Reviews from users: 46806
 Ratings
Ratings - Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about We.TIL 36 : 엔티티와 테이블의 차이 엔티티는 데이터베이스나 SQL상에 존재하지 않는다. 테이블과 달리 엔티티는 실제로 존재하지 않는 아닌 일종의 개념이다. 그러나 테이블은 데이터베이스 … …
- Most searched keywords: Whether you are looking for We.TIL 36 : 엔티티와 테이블의 차이 엔티티는 데이터베이스나 SQL상에 존재하지 않는다. 테이블과 달리 엔티티는 실제로 존재하지 않는 아닌 일종의 개념이다. 그러나 테이블은 데이터베이스 … 엔티티는 데이터베이스나 SQL상에 존재하지 않는다. 테이블과 달리 엔티티는 실제로 존재하지 않는 아닌 일종의 개념이다.그러나 테이블은 데이터베이스나 SQL에 실제로 존재하며 물리적인 구조를 지니고 있다.엔티티는 테이블이 될수도 있고 안 될수도 있다. 엔티티는 CDM(C
- Table of Contents:
WeTIL
첫 번째
두 번째
세 번째
스프링부트 JPA @Entity @Table 차이점 정리
- Article author: wakestand.tistory.com
- Reviews from users: 48061 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about 스프링부트 JPA @Entity @Table 차이점 정리 스프링부트 JPA 에서 Entity에 해당하는 파일에 @Entity @Table 어노테이션을 사용할 수 있는데 일단 @Entity는 필수로 들어가야 하고 @Entity만 사용 … …
- Most searched keywords: Whether you are looking for 스프링부트 JPA @Entity @Table 차이점 정리 스프링부트 JPA 에서 Entity에 해당하는 파일에 @Entity @Table 어노테이션을 사용할 수 있는데 일단 @Entity는 필수로 들어가야 하고 @Entity만 사용 … 스프링부트 JPA 에서 Entity에 해당하는 파일에 @Entity @Table 어노테이션을 사용할 수 있는데 일단 @Entity는 필수로 들어가야 하고 @Entity만 사용했을 경우 DB와 연결 시 테이블명은 클래스명과 동일하게 설..
- Table of Contents:
댓글0
공지사항
최근글
인기글
최근댓글
전체 방문자
1. 데이터 모델링의 이해 : 네이버 블로그
- Article author: m.blog.naver.com
- Reviews from users: 48906 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about 1. 데이터 모델링의 이해 : 네이버 블로그 엔티티 -> 테이블 … 엔티티=인스턴스의 집합 … 각 어커런스를 구분할 수 있는 구분자이나대표성에 따라 참조관계를 연결 할 수 있고 없고의 차이). …
- Most searched keywords: Whether you are looking for 1. 데이터 모델링의 이해 : 네이버 블로그 엔티티 -> 테이블 … 엔티티=인스턴스의 집합 … 각 어커런스를 구분할 수 있는 구분자이나대표성에 따라 참조관계를 연결 할 수 있고 없고의 차이).
- Table of Contents:
카테고리 이동
Enjoy My life
이 블로그
SQLP
카테고리 글
카테고리
이 블로그
SQLP
카테고리 글
@Table과 @Entity 차이점 – 인프런 | 질문 & 답변
- Article author: www.inflearn.com
- Reviews from users: 13146 Ratings
- Top rated: 4.5
- Lowest rated: 1
- Summary of article content: Articles about @Table과 @Entity 차이점 – 인프런 | 질문 & 답변 @Table과 @Entity 차이점. 휴식중인 소. · 2020.10.10. Order 객체를 매핑할때, db에서 테이블명을 orders로 설정하고 싶어 @Table(name=”orders”)로 하는 것을 … …
- Most searched keywords: Whether you are looking for @Table과 @Entity 차이점 – 인프런 | 질문 & 답변 @Table과 @Entity 차이점. 휴식중인 소. · 2020.10.10. Order 객체를 매핑할때, db에서 테이블명을 orders로 설정하고 싶어 @Table(name=”orders”)로 하는 것을 … Order 객체를 매핑할때, db에서 테이블명을 orders로 설정하고 싶어 @Table(name=’orders’)로 하는 것을 보았습니다.
이말은 실제 클래스명과 다르게 테이블명을 바꾼다 로 알수 있는데 @Entity(name =’orders’)로 그냥 하면 되는게 아닌… - Table of Contents:

Entity와 Table
- Article author: b-programmer.tistory.com
- Reviews from users: 37587 Ratings
- Top rated: 4.6
- Lowest rated: 1
- Summary of article content: Articles about Entity와 Table 그건 바로 객체를 이용해서 테이블을 생성하고 이용하고 싶기 때문이라고 생각합니다. 물론 마이바티스 처럼 자바에서 쿼리를 작성해서 DB에 연동시키는 … …
- Most searched keywords: Whether you are looking for Entity와 Table 그건 바로 객체를 이용해서 테이블을 생성하고 이용하고 싶기 때문이라고 생각합니다. 물론 마이바티스 처럼 자바에서 쿼리를 작성해서 DB에 연동시키는 … Jpa를 공부하다보면 제일 먼저 Entity를 만나볼 수 있습니다. 이걸 보고 있으면 객체이면서 테이블 같은 오묘한 기분을 느낄 수 있습니다. 이는 사실 JPA의 특징의 영속성과 큰 연관이 있습니다. 영속성 영속성이..
- Table of Contents:
Header Menu
Main Menu
Entity와 Table
‘JPA’ 관련 글
Sidebar – Right
Sidebar – Footer 1
Sidebar – Footer 2
Sidebar – Footer 3
Sidebar – Footer 4
Copyright © 프로그래밍 프로그래머는 아름다워 All Rights Reserved
Designed by JB FACTORY
티스토리툴바

엔터티 – DATA ON-AIR
- Article author: dataonair.or.kr
- Reviews from users: 16530 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about 엔터티 – DATA ON-AIR 엔터티를 표현하는 방법은 각각의 표기법에 따라 조금씩 차이는 있지만 대부분 … 또한 코드성 엔터티는 물리적으로 테이블과 프로그램 구현 이후에도 외부키에 의한 … …
- Most searched keywords: Whether you are looking for 엔터티 – DATA ON-AIR 엔터티를 표현하는 방법은 각각의 표기법에 따라 조금씩 차이는 있지만 대부분 … 또한 코드성 엔터티는 물리적으로 테이블과 프로그램 구현 이후에도 외부키에 의한 … 1. 엔터티의 개념 데이터 모델을 이해할 때 가장 명확하게 이해해야 하는 개념 중에 하나가 바로 엔터티(Entity)이다. 이것은 우리말로 실체, 객체라고 번역하기도 하는데 실무적으로 엔터티라는 외래어를 많이 사용하기 때문에 본 가이드에서는 엔터티라는 용어를 그대로 사용하기로 한다. 엔터티에 대해서 데이터 모델과 데이터베이스에 권위자가 정의한 사항은 다음과 같다. 변별할 수 있는 사물 – Peter Chen (1976) – 데이터베이스 내에서 변별 가능한 객체 – C.J Date (1986) – 정보를 저장할 수 있는 어떤 것 – James Martin (1989) – 정보가 저장될 수 있는 사람, 장소, 물건, 사건 그리고 개념 등 – Thomas Bruce (1992) – 위 정의들의 공통점은 다음과 같다. 엔터티는 사람, 장소, 물건, 사건, 개념 등의 명사에 해당한다. 엔터티는 업무상 관리가 필요한 관심사에 해당한다. 엔터티는 저장이 되기 위한 어떤 것(Thing)이다. 엔터티란 “업무에 필요하고 유용한 정보를 저장하고 관리하기 위한 집합적인 것(Thing)”으로 설명할 수 있다. 또는, 엔터티는 업무 활동상 지속적인 관심을 가지고 있어야 하는 대상으로서 그 대상들 간에 동질성을 지닌 인스턴스들이나 그들이 행하는 행위의 집합으로 정의할 수 있다. 엔터티는 그 집합에 속하는 개체들의 특성을 설명할 수 있는 속성(Attribute)을 갖는데, 예를 들어 ‘학생’이라는 엔터티는 학번, 이름, 이수학점, 등록일자, 생일, 주소, 전화번호, 전공 등의 속성으로 특징지어질 수 있다. 이러한 속성 가운데에는 엔터티 인스턴스 전체가 공유할 수 있는 공통 속성도 있고, 엔터티 인스턴스 중 일부에만 해당하는 개별 속성도 있을 수 있다. 또한 엔터티는 인스턴스의 집합이라고 말할 수 있고, 반대로 인스턴스라는 것은 엔터티의 하나의 값에 해당한다고 정의할 수 있다. 예를 들어 과목은 수학, 영어, 국어가 존재할 수 있는데 수학, 영어, 국어는 각각이 과목이라는 엔터티의 인스턴스들이라고 할 수 있다. 또한 사건이라는 엔터티에는 사건번호2010-001, 2010-002 등의 사건이 인스턴스가 될 수 있다. 엔터티를 이해할 때 눈에 보이는(Tangible)한 것만 엔터티로 생각해서는 안되며 눈에 보이지 않는 개념 등에 대해서도 엔터티로서 인식을 할 수 있어야 한다. 실제 업무상에는 눈에 보이지 않는 것(Thing)이 엔터티로 도출되는 경우가 많기 때문에 더더욱 주의할 필요가 있다. 2. 엔터티와 인스턴스에 대한 내용과 표기법 엔터티를 표현하는 방법은 각각의 표기법에 따라 조금씩 차이는 있지만 대부분 사각형으로 표현된다. 다만 이 안에 표현되는 속성의 표현방법이 조금씩 다를 뿐이다. 엔터티와 엔터티간의 ERD를 그리면 [그림 Ⅰ-1-15]와 같이 표현할 수 있다. [그림 Ⅰ-1-15]에서 과목, 강사, 사건은 엔터티에 해당하고 수학, 영어는 과목이라는 엔터티의 인스턴스이고 이춘식, 조시형은 강사라는 엔터티의 인스턴스이며 사건번호인 2010-001, 2010-002는 사건 엔터티에 대한 인스턴스에 해당한다. ※ 참고 : 오브젝트 모델링에는 클래스(Class)와 오브젝트(Object)라는 개념이 있다. 클래스는 여러 개의 오브젝트를 포함하는 오브젝트 깡통이다. 이러한 개념은 정보공학의 엔터티가 인스턴스를 포함하는 개념과 비슷하다. 위의 엔터티와 인스턴스를 표현하면 [그림 Ⅰ-1-16]과 같다. 3. 엔터티의 특징 엔터티는 다음과 같은 특징을 가지고 있으며 만약 도출된 엔터티가 다음의 성질을 만족하지 못하면 적절하지 않은 엔터티일 확률이 높다. 반드시 해당 업무에서 필요하고 관리하고자 하는 정보이어야 한다.(예. 환자, 토익의 응시횟수, …) 유일한 식별자에 의해 식별이 가능해야 한다. 영속적으로 존재하는 인스턴스의 집합이어야 한다.(‘한 개’가 아니라 ‘두 개 이상’) 엔터티는 업무 프로세스에 의해 이용되어야 한다. 엔터티는 반드시 속성이 있어야 한다. 엔터티는 다른 엔터티와 최소 한 개 이상의 관계가 있어야 한다. 가. 업무에서 필요로 하는 정보 엔터티 특징의 첫 번째는 반드시 시스템을 구축하고자 하는 업무에서 필요로 하고 관리하고자 하는 정보여야 한다는 점이다. 예를 들어 환자라는 엔터티는 의료시스템을 개발하는 병원에서는 반드시 필요한 엔터티이지만 일반회사에서 직원들이 병에 걸려 업무에 지장을 준다하더라도 이 정보를 그 회사의 정보로서 활용하지는 않을 것이다. 즉 시스템 구축 대상인 해당업무에서 그 엔터티를 필요로 하는가를 판단하는 것이 중요하다. 사람이 살아가면서 환자는 발생할 수 밖에 없다. 그러나 일반회사의 인사시스템에서는 비록 직원들에 의해서 환자가 발생이 되지만 인사업무 영역에서 환자를 별도로 관리할 필요가 없다. 다른 예로 병원에서는 환자가 해당 업무의 가장 중요한 엔터티가 되어 꼭 관리해야 할 엔터티가 된다. 이와 같이 엔터티를 도출할 때는 업무영역 내에서 관리할 필요가 있는지를 먼저 판단하는 것이 중요하다. 나. 식별이 가능해야 함 두 번째는 식별자(Unique Identifier)에 의해 식별이 가능해야 한다는 점이다. 어떤 엔터티이건 임의의 식별자(일련번호)를 부여하여 유일하게 만들 수는 있지만, 엔터티를 도출하는 경우에 각각의 업무적으로 의미를 가지는 인스턴스가 식별자에 의해 한 개씩만 존재하는지 검증해 보아야 한다. 유일한 식별자는 그 엔터티의 인스턴스만의 고유한 이름이다. 두 개 이상의 엔터티를 대변하면 그 식별자는 잘못 설계된 것이다. 예를 들어 직원을 구분할 수 있는 방법은 이름이나 사원번호가 될 수가 있다. 그러나 이름은 동명이인(同名異人)이 될 수 있으므로 유일하게 식별될 수 없다. 사원번호는 회사에 입사한 사람에게 고유하게 부여된 번호이므로 유일한 식별자가 될 수 있는 것이다. 다. 인스턴스의 집합 세 번째는 영속적으로 존재하는 인스턴스의 집합이 되어야 한다는 점이다. 엔터티의 특징 중 “한 개”가 아니라 “두 개 이상”이라는 집합개념은 매우 중요한 개념이다. 두 개 이상이라는 개념은 엔터티뿐만 아니라 엔터티간의 관계, 프로세스와의 관계 등 업무를 분석하고 설계하는 동안 설계자가 모든 업무에 대입해보고 검증해?러 개의 인스턴스를 포함한다. 라. 업무프로세스에 의해 이용 네 번째는 업무프로세스(Business Process)가 그 엔터티를 반드시 이용해야 한다는 점이다. 첫 번째 정의에서처럼 업무에서 반드시 필요하다고 생각하여 엔터티로 선정하였는데 업무프로세스에 의해 전혀 이용되지 않는다면 업무 분석이 정확하게 안되어 엔터티가 잘못 선정되거나 업무프로세스 도출이 적절하게 이루어지지 않았음을 의미한다. 이러한 경우는 데이터 모델링을 할 때 미처 발견하지 못하다가 프로세스 모델링을 하면서 데이터 모델과 검증을 하거나, 상관 모델링을 할 때 엔터티와 단위프로세스를 교차 점검하면서 문제점이 도출된다. [그림 Ⅰ-1-20]과 같이 업무프로세스에 의해 CREATE, READ, UPDATE, DELETE 등이 발생하지 않는 고립된 엔터티의 경우는 엔터티를 제거하거나 아니면 누락된 프로세스가 존재하는지 살펴보고 해당 프로세스를 추가해야 한다. 마. 속성을 포함 다섯 번째는 엔터티에는 반드시 속성(Attributes)이 포함되어야 한다는 점이다. 속성을 포함하지 않고 엔터티의 이름만 가지고 있는 경우는 관계가 생략되어 있거나 업무 분석이 미진하여 속성정보가 누락되는 경우에 해당한다. 또한 주식별자만 존재하고 일반속성은 전혀 없는 경우도 마찬가지로 적절한 엔터티라고 할 수 없다. 단, 예외적으로 관계엔터티(Associative Entity)의 경우는 주식별자 속성만 가지고 있어도 엔터티로 인정한다. 바. 관계의 존재 여섯 번째는 엔터티는 다른 엔터티와 최소 한 개 이상의 관계가 존재해야 한다는 것이다. 기본적으로 엔터티가 도출되었다는 것은 해당 업무내에서 업무적인 연관성(존재적 연관성, 행위적 연관성)을 가지고 다른 엔터티와의 연관의 의미를 가지고 있음을 나타낸다. 그러나 관계가 설정되지 않은 엔터티의 도출은 부적절한 엔터티가 도출되었거나 아니면 다른 엔터티와 적절한 관계를 찾지 못했을 가능성이 크다. 단, 데이터 모델링을 하면서 관계를 생략하여 표현해야 하는 경우는 다음과 같은 통계성 엔터티 도출, 코드성 엔터티 도출, 시스템 처리시 내부 필요에 의한 엔터티 도출과 같은 경우이다. 1) 통계를 위한 엔터티의 경우는 업무진행 엔터티로부터 통계업무만(Read Only)을 위해 별도로 엔터티를 다시 정의하게 되므로 엔터티간의 관계가 생략되는 경우에 해당한다. 2) 코드를 위한 엔터티의 경우 너무 많은 엔터티와 엔터티간의 관계 설정으로 인해 데이터 모델의 읽기효율성(Readability)이 저하되어 도저히 모델링 작업을 진행할 수 없게 된다. 또한 코드성 엔터티는 물리적으로 테이블과 프로그램 구현 이후에도 외부키에 의한 참조무결성을 체크하기 위한 규칙을 데이터베이스 기능에 맡기지 않는 경우가 대부분이기 때문에 논리적으로나 물리적으로 관계를 설정할 이유가 없다. 3) 시스템 처리시 내부 필요에 의한 엔터티(예를 들어, 트랜잭션 로그 테이블 등)의 경우 트랜잭션이 업무적으로 연관된 테이블과 관계 설정이 필요하지만 이 역시 업무적인 필요가 아니고 시스템 내부적인 필요에 의해 생성된 엔터티이므로 관계를 생략하게 된다. 4. 엔터티의 분류 엔터티는 엔터티 자신의 성격에 의해 실체유형에 따라 구분하거나 업무를 구성하는 모습에 따라 구분이 되는 발생시점에 의해 분류해 볼 수 있다. 가. 유무(有無)형에 따른 분류 일반적으로 엔터티는 유무형에 따라 유형엔터티, 개념엔터티, 사건엔터티로 구분된다. 유형엔터티(Tangible Entity)는 물리적인 형태가 있고 안정적이며 지속적으로 활용되는 엔터티로 업무로부터 엔터티를 구분하기가 가장 용이하다. 예를 들면, 사원, 물품, 강사 등이 이에 해당된다. 개념엔터티(Conceptual Entity)는 물리적인 형태는 존재하지 않고 관리해야 할 개념적 정보로 구분이 되는 엔터티로 조직, 보험상품 등이 이에 해당된다. 사건 엔터티(Event Entity)는 업무를 수행함에 따라 발생되는 엔터티로서 비교적 발생량이 많으며 각종 통계자료에 이용될 수 있다. 주문, 청구, 미납 등이 이에 해당된다. 나. 발생시점(發生時點)에 따른 분류 엔터티의 발생시점에 따라 기본/키엔터티(Fundamental Entity, Key Entity), 중심엔터티(Main Entity), 행위엔터티(Active Entity)로 구분할 수 있다. 1) 기본엔터티 기본엔터티란 그 업무에 원래 존재하는 정보로서 다른 엔터티와 관계에 의해 생성되지 않고 독립적으로 생성이 가능하고 자신은 타 엔터티의 부모의 역할을 하게 된다. 다른 엔터티로부터 주식별자를 상속받지 않고 자신의 고유한 주식별자를 가지게 된다. 예를 들어 사원, 부서, 고객, 상품, 자재 등이 기본엔터티가 될 수 있다. 2) 중심엔터티 중심엔터티란 기본엔터티로부터 발생되고 그 업무에 있어서 중심적인 역할을 한다. 데이터의 양이 많이 발생되고 다른 엔터티와의 관계를 통해 많은 행위엔터티를 생성한다. 예를 들어 계약, 사고, 예금원장, 청구, 주문, 매출 등이 될 수 있다. 3) 행위엔터티 행위엔터티는 두 개 이상의 부모엔터티로부터 발생되고 자주 내용이 바뀌거나 데이터량이 증가된다. 분석초기 단계에서는 잘 나타나지 않으며 상세 설계단계나 프로세스와 상관모델링을 진행하면서 도출될 수 있다. 예를 들어 주문목록, 사원변경이력 등이 포함된다. 다. 엔터티 분류 방법의 예 [그림 Ⅰ-1-23]은 두 가지 엔터티 분류 방법에 대한 예를 나타낸 것이다. 이 밖에도 엔터티가 스스로 생성될 수 있는지 여부에 따라 독립엔터티인지 의존엔터티인지를 구분할 수도 있다. 5. 엔터티의 명명 엔터티를 명명하는 일반적인 기준은 용어를 사용하는 모든 표기법이 다 그렇듯이 첫 번째는 가능하면 현업업무에서 사용하는 용어를 사용한다. 두 번째는 가능하면 약어를 사용하지 않는다. 세 번째는 단수명사를 사용한다. 네 번째는 모든 엔터티에서 유일하게 이름이 부여되어야 한다. 다섯 번째는 엔터티 생성의미대로 이름을 부여한다. 첫 번째에서 네 번째에 해당하는 원칙은 대체적으로 잘 지켜진다. 그러나 다섯 번째 원칙인 “엔터티 생성의미대로 이름을 부여한다.”에 대해서는 적절하지 못한 엔터티명이 부여되는 경우가 빈번하게 발생한다. 중심엔터티에서도 간혹 적절하지 못한 엔터티명을 사용한 경우가 발생되고 행위엔터티의 경우에는 꽤 많은 경우에 적절하지 못한 엔터티명을 사용하는 경우가 발생된다. 예를 들어, 고객이 어떤 제품? 주문목록이라고도 할 수 있고 고객제품이라고 할 수 있다. 만약 고객제품이라고 하면 ‘고객이 주문한 제품’인지 아니면 ‘고객의 제품’인지 의미가 애매모호해질 수 있게 된다. 엔터티의 이름을 업무목적에 따라 생성되는 자연스러운 이름을 부여해야 하는데 이와 상관없이 임의로 이름을 부여하게 되면 프로젝트에서는 커뮤니케이션 오류로 인해 문제를 야기할 수 있게 된다.
- Table of Contents:
JPA @Entity @Table @Column
- Article author: jojelly.tistory.com
- Reviews from users: 37842 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about JPA @Entity @Table @Column JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수 … 중 nullable = false 가 있다. null값을 받지 못하도록 하는건데 @NotNull과의 차이는 …
- Most searched keywords: Whether you are looking for JPA @Entity @Table @Column JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수 … 중 nullable = false 가 있다. null값을 받지 못하도록 하는건데 @NotNull과의 차이는 @Entity • @Entity가 붙은 클래스는 JPA가 관리, 엔티티라 한다. • JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수 • 주의 • 기본 생성자 필수(파라미터가 없는 public 또는 protected 생성자) • fin..
- Table of Contents:
태그
관련글
댓글0
공지사항
최근글
인기글
최근댓글
태그
전체 방문자
티스토리툴바
케네스로그 :: [DB] 데이터베이스 용어 정리 – 필드, 레코드, 엔티티, 특성
- Article author: 93jpark.tistory.com
- Reviews from users: 19350 Ratings
- Top rated: 4.5
- Lowest rated: 1
- Summary of article content: Articles about 케네스로그 :: [DB] 데이터베이스 용어 정리 – 필드, 레코드, 엔티티, 특성 엑셀과 데이터베이스 엑셀의 테이블은 행과 열로 구분되며, 다양.. … 엔티티와 레코드의 차이점 (Entity vs Records) 레코드는 실제 데이터베이스 … …
- Most searched keywords: Whether you are looking for 케네스로그 :: [DB] 데이터베이스 용어 정리 – 필드, 레코드, 엔티티, 특성 엑셀과 데이터베이스 엑셀의 테이블은 행과 열로 구분되며, 다양.. … 엔티티와 레코드의 차이점 (Entity vs Records) 레코드는 실제 데이터베이스 … 이전 글에서 데이터, 데이터베이스, 그리고 SQL에 대한 간략한 설명을 했었습니다. 이번에는 데이터베이스의 구성과 용어들에 정리해보겠습니다. 엑셀과 데이터베이스 엑셀의 테이블은 행과 열로 구분되며, 다양..INTJ-풀스택 개발자 취준생
- Table of Contents:
엑셀과 데이터베이스
데이터베이스 용어
티스토리툴바
![케네스로그 :: [DB] 데이터베이스 용어 정리 - 필드, 레코드, 엔티티, 특성](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcrZ9sD%2Fbtrr2ywkSFB%2FxUXL4KTuClM3RhQ65cvg2K%2Fimg.png)
[JPA] 엔티티와 매핑. @Entity, @Table, @Id, @Column..
- Article author: data-make.tistory.com
- Reviews from users: 26926 Ratings
- Top rated: 4.6
- Lowest rated: 1
- Summary of article content: Articles about [JPA] 엔티티와 매핑. @Entity, @Table, @Id, @Column.. valate : DB 테이블과 엔티티 매핑정보를 비교해서 차이가 있으면 경고를 남기고 애플리케이션을 실행하지 않음. DDL을 수행하지 않음. none : 자동 … …
- Most searched keywords: Whether you are looking for [JPA] 엔티티와 매핑. @Entity, @Table, @Id, @Column.. valate : DB 테이블과 엔티티 매핑정보를 비교해서 차이가 있으면 경고를 남기고 애플리케이션을 실행하지 않음. DDL을 수행하지 않음. none : 자동 … | 엔티티와 매핑 객체와 테이블 매핑 : @Entity, @Table 기본 키 매핑 : @Id 필드와 컬럼 매핑 : @Column 연관관계 매핑 : @ManyToOne, @JoinColumn 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23..
- Table of Contents:
티스토리 뷰
티스토리툴바
![[JPA] 엔티티와 매핑. @Entity, @Table, @Id, @Column..](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F99E311485FE971491C)
See more articles in the same category here: toplist.maxfit.vn/blog.
스프링부트 JPA @Entity @Table 차이점 정리
반응형
스프링부트 JPA 에서 Entity에 해당하는 파일에
@Entity
@Table
어노테이션을 사용할 수 있는데
일단 @Entity는 필수로 들어가야 하고
@Entity만 사용했을 경우 DB와 연결 시
테이블명은 클래스명과 동일하게 설정된다
즉 @Entity 어노테이션을 사용한 상태에서
클래스명이 CrudEntity일 경우
DB에서 CrudEntity 테이블로 연결된다는 거다
@Entity(name = “엔티티명”)
으로 테이블명을 지정해 줄 경우에는
이후 EntityManager 등을 이용해 쿼리를 사용할 경우
createQuery(“select .. from 엔티티명”)
이렇게 사용할 수 있게 된다
반면 @Table의 경우에는
외부에서 호출하는 용도가 아닌
실제 DB에 붙을 테이블명 어노테이션을 말하는데
@Entity와 조합을 해서 사용해보면
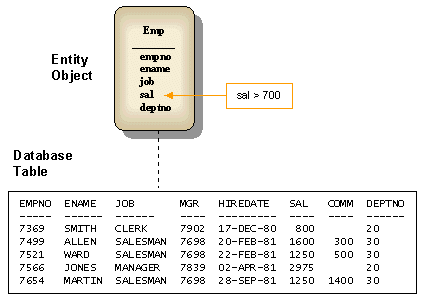
위 이미지와 같이
@Entity
@Table(name = “테이블명”)
이렇게 지정을 해 놓을 경우
createQuery(select m from 엔티티클래스명)
으로 호출을 해 주면
호출은 엔티티클래스명으로 하지만
실제 DB에는 테이블명의 테이블로 붙게 된다
반응형
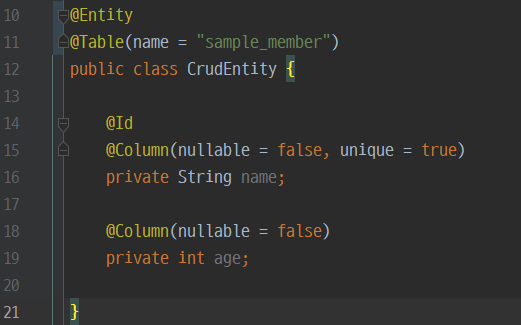
1. 데이터 모델링의 이해
엔티티,속성,관계..
엔티티 -> 테이블
속성 -> 컬럼
인스턴스 -> 행
엔티티셋 -> 레코드 집합
엔티티타입 -> 속성 집합
또는
엔티티=인스턴스의 집합
인스턴스=논리적 개념의 하나의 thing
엔티티집합=엔티티의 집합
엔티티= 인스턴스와 동일하게 봄
1. 모델링의 이해
가. 모델링의 정의
1)모델이란 현실 세계의 추상화된 반영
나. 모델링의 특징
1) 추상화 : 다양한 현상을 일정한 양식인 표기법의 의해 표현함
2) 단순화 : 복잡한 현실세계의 규약을 제한된 표기법이나 언어로 쉽게 이해하도록 하는 개념
3) 명확화 : 정확하게 현상을 기술하는 것을 의미
다. 모델링의 세 가지 관점
1) 데이터관점 : 업무가 어떤 데이터와 관련이 있는지 또는 데이터간의 관계는 무엇인지에 대해서 모델링하는 방법
2) 프로세스 관점 : 업무가 실제하고 있는 일은 무었인지 또는 무엇을 해야하는지를 모델링하는 방법
3) 데이터와 프로세스의 상관관점 : 업무가 처리하는 일의 방법에 따라 데이터는 어떻게 영향을 받고 있는지 모델링하는 방법
2. 데이터 모델의 기본 개념의 이해
가. 데이터 모델링의 정의
: 정보시스템을 구축하기 위해, 해당 업무에 어떤 데이터가 존재하는지 또는 업무가 필요로 하는 정보는 무엇인지를 분석하는 방법,
기업 업무에 대한 종합적인 이해를 바탕으로 데이터에 존재하는 업무 규칙에 대하여 참 또는 거짓을 판별할 수 있는 사실을 데이터에 접근하는 방법, 사람, 전산화와는 별개의 관점에서 이를 명확하게 표현하는 추상화 기법
실무적으로 해석할 때는 업무에서 필요로 하는 데이터를 시스템 구축 방법론에 의해 분석하고 설계하여 정보시스템을 구축하는 과정으로 정의
* 데이터 모델일 하는 주요 이유 – 데이터 모델링 자체로 업무를 설명 하고 분석하는 부분도 매우 중요한 의미를 갖는다.
정보시스템 구축의 대상이 되는 업무 내용을 정확하게 분석하는 것, 실제 데이터 베이스를 생성하여 개발 및 데이터관리에 사용하기 위한것
나. 데이터 모델이 제공하는 기능
1) 시스템을 현재 또는 원하는 모습으로 가시화하도록 도와준다.
2) 시스템의 구조와 행동을 명세화 할 수 있게 한다.
3) 시스템을 구축하는 구조화된 틀을 제공한다.
4) 다양한 영역에 집중하기 위해 다른 영역의 세부사항은 숨기는 다양한 관점을 제공한다.
5) 특정목표에 따라 구체화된 상세 수준의 표현방법을 제공한다.
6) 시스템을 구축하는 과정에서 결정한 것을 문서화 한다.
3. 데이터 모델링의 중요성 및 유의점
*데이터 모델링의 중요성
가. 파급효과 : 데이터 구조의 변경으로 인한 일련의 변경작업은 전체 시스템 구축 프로젝트에서 큰 위험요소
나 복잡한 정보 요구사항의 간결한 표현 : 요구사항을 파악하는 것보다 데이터 모델을 리뷰하면서 파악하는 것이 훨씬 빠른 방법.설계도면
다. 데이터 품질 : 데이터는 기업의 중요한 자산. 초반에는 잘 모르나 오랜 기간 지나면 문제가 대두 될 수 있다.
*데이터 모델링의 유의점
가. 중복 : 여러장소에 같은 정보를 저장하지 않아야 함
나. 비유연성 : 데이터 정의를 데이터 사용 프로세스와 분리하여,데이터 혹은 프로세스의 작은 변화가 어플리케이션과 데이터베이스에 변화를 일으킬 가능성을 줄인다.
다. 비일관성 : 데이터와 데이터간 상호 연관 관계에 대한 명확한 정의는 비일관성에 대한 위험을 예방함
4. 데이터 모델링의 3단계 진행
가. 개념적 데이터 모델링 : 추상화 수준이 높고 업무중심적이고 포괄적인 수준의 모델링 진행. 전사적 데이터 모델링, EA수립시 많이 이용
나. 논리적 데이터 모델링 : 시스템으로 구축하고자 하는 업무에 대해 Key, 속성, 관계 등을 정확하게 표현, 재사용성이 높음
다. 물리적 데이터 모델링 : 실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계
5.프로젝트 생명주기에서 데이터 모델링
: 일반적으로는 계획 또는 분석단계에서 개념적 데이터 모델링 분석단계에서 논리적 데이터 모델링 설계단계에서 물리적 데이터 모델ㅇ링이 수행된다. 단, 현실 프로젝트에서는 개념적 데이터 모델이 생략된 개념/논리 데이터 모델링이 분석단계 때 대부분 수행된다.
6. 데이터 모델링에서 데이터 독립성의 이해
가. 데이터독립성의 필요성
: 데이터 독립성은 지속적으로 증가하는 유지보수 비용을 절감하고 데이터 복잡도를 낮추며 중복된 데이터를 줄이기 위한 목적, 또한 끊임없이 요구되는 사용자 요구사항에 대해 화면과 데이터베이스 간에 서로 독립성을 유지하기 위한 목적으로 데이터 독립성 개념이 출현했다고 할 수 있다.
*반대어 데이터종속성 :
– 각 view의 독립성을 유지하고 계층별 View에 영향을 주지 않고 변경이 가능하다.
– 단계별 Schema에 따라 데이터 정의어와 데이터 조작어가 다름을 제공한다.
나. 데이터베이스 3단계구조
– 외부단계 : 사용자와가까운 단계로 사용자 개개인이 보는 자료에 대한 관점과 관련이 있는 부분, 사용자가 처리하고자 하는데이터유형에 따라 관점에 따라, 방법에 따라 다른 스키마 구조를 가지고 있다.
– 논리적 데이터독립성
– 개념적단계 : 사용자가처리하는 데이터 유형의 공통적인 사항을 처리하는 통합된 뷰를 스키마 구조로 디자인한 형태. 우리가 쉽게이해하는 데이터 모델은 사용자가 처리하는 통합된 뷰를 설계하는 도구로 이해해도 무방함
– 물리적 데이터독립성
– 내부적단계 : 데이터가물리적으로 저장된 방법에 대한 스키마 구조를 말한다.
다. 데이터독립성 요소
– 외부스키마 : View 단계여러개의 사용자 관점으로 구성, 즉 개개 사용자 단계로서 프로그래머가 개개 사용자가 보는 개인적 DB 스키마, DB의 개개 사용자나 응용프로그래머가 접근하는 DB정의
* 사용자 관점 접근하는 특성에 따른 스키마 구성
– 개념스키마 : 개념단계하나의 개념적 스키마로 구성 모든 사용자 관점을 통합한 조직 전체의 DB를 기술하는 것. 모든 응용시스템들이나 사용자들이 필요로 하는 데이터를 통합한 조직 전체의DB를 기술한 것으로 DB에 저장되는 데이터와 그들간의 관계를 표현하는 스키마
*통합관점
– 내부스키마 : 내부단계, 내부 스키마로 구성, DB가 물리적으로 저장된 형식. 물리적 장치에서 데이터가 실제적으로 저장되는 방법을 표현하는 스키마
* 물리적 저장구조
라. 두 영역의 데이터독립성
– 논리적 독립성 : 개념스키마가변경되어도 외부 스키마에는 영향을 미치지 않도록 지원하는 것. 논리적 구조가 변경되어도 응용프로그램에는영향 없음
* 사용자 특성에 맞는 변경가능, 통합구조변경가능
– 물리적 독립성 : 내부스키마가변경되어도 외부/개념 스키마는 영향을 받지 않도록 지원하는 것. 저장장치의구조변경은 응용프로그램과 개념스키마에 영향없음
* 물리적 구조 영향 없이 개념구조 변경가능, 개념구조 영향 없이 물리적인 구조 변경가능
마. 사상(Mapping)
– 외부적/개념적사상(논리적 사상) : 외부적 뷰와 개념적 뷰의 상호 관련성을 정의함
* 사용자가 접근하는 형식에 따라 다른 타입의 필드를 가질 수 있음. 개념적 뷰의 필드 타입은 변화가 없음
– 개념적/내부적 사상(물리적 사상) : 개념적 뷰와 저장된 데이터베이스의 상호관련성을 정의함
* 만약 저장된 데이터베이스 구조가 바뀐다면 개념적/내부적/ 사상이 바뀌어야 함. 그래야개념적 스키마가 그대로 남아있게 됨
7. 데이터 보델링의 중요한 세 가지 개념
가. 데이터 모델링의 세 가지 요소
1) 업무가 관여하는 어떤 것(Things)
2) 어떤 것이 가지는 성격(Attributes)
3) 업무가 관여하는 어떤 것 간의 관계(Relationsships)
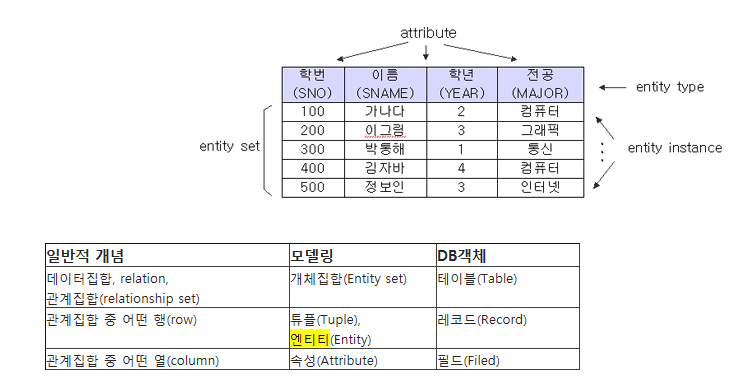
*엔티티, 속성, 관계
개념 – 복수/집합개념,타입/클래스 – 개별/단수개념 , 어커런스/인스턴스
어떤 것 – 엔터티 타입 – 엔터티
어떤 것 – 엔터티 – 인스턴스/어커런스
어떤 것간의 연관 – 관계 – 패어링
어떤 것의 성격 – 속성 – 속성값
8. 데이터 모델링의 이해관계자
가. 이해관계자의 데이터 모델링 주용성 인식
나. 데이터 모델링의 이해관계자
1) 정보시스템을 구축하는 모든사람
2) 현업업무전문가
9. 데이터 모델의 표기법인 ERD의이해
가. 데이터 모델 표기법
나. ERD 표기법을 이용하여 모델링하는 방법
1) ERD 작업순서
(1) 엔터티를 그린다.
(2) 엔터티를 적절하게 배치한다.
(3) 엔터티간 관계를 설정한다.
(4) 관계명을 기술한다.
(5) 관계의 참여도를 기술한다.
(6) 관계의 필수여부를 기술한다.
2) 엔터티 배치
(1) 가장 중용한 엔터티를 왼쪽상단부터 배치
(2) 업무흐름에 중심이 되는 엔터티를 중아에 배치
(3) 업무를 진행하는 중심엔터티와 관계를 갖는 엔터티들은 중심에배치된 엔터티를 주위에 배치하도록 한다.
3) ERD 관계의 연결
4) ERD 관계명의 표시
: 명확하게 관계명을 표시 (주문을하고있다 X, 주문하다 O)
5) ERD 관계 관계차수의 선택성의 표시
10. 좋은 데이터 모델의 요소
가. 완전성
: 업무에서 필요로 하는 모든 데이터가 데이터 모델에 정의 되어 있어야한다.
나. 중복배제(Non-Redundancy)
: 하나의 데이터베이스 내에 동일한 사실은 한 번만 기록하여야 한다.
다. 업무규칙(BusinessRules)
: 데이터 모델링 과정에서 도출되고 규명되는 수많은 업무규칙을 데이터모델에 표현하고 이를 해당 데이터 모델을 활용하는 모든 사용자가 공유할 수 있도록 제공
* 특히 데이터 아키텍처에서 언급되는 논리 데이터 모델에서 이러한요소들이 포함되어야 함은 매우 중요하다.
라. 데이터 재사용(DataReusablility)
: 데이터의 재사용성을 향상시키고자 한다면 데이터의 통합성과 독립성에대해서 충분히 고려해야 한다.
* 통합 모델이 중요.
마. 의사소통
: 데이터 분석 과정에서 도축 되는 많은 업무규칙 들은 해당 정보시스템을운용, 관리하는 많은 관련자들이 설계자가 정의한 업무 규칙들을 동일한 의미로 받아들이고 정보시스템을활용할 수 있게 하는 역할을 하게 된다.
바. 통합성(Integration)
: 가장 바람직한 데이터 구조의 형태는 통일한 데이터는 조직의 전체에서한번 만 정의되고 이를 여러 다른 영역에서 참조 활용하는 것이다
제 2절 엔티티
1. 엔티티의 개념
– 변별할 수 있는 시물 PeterChen (1976)
– 데이터베이스 내에서 변별 가능한 객체 C.J Date (1986)
– 정보를 저장할 수 있는 어떤 것 James Martin (1989)
– 정보가 저장될 수 있는 사람, 장소, 툴건, 사건 그리고 개념등 Thomas Bruce (1992)
위정의들의 공통점은 다음과 같다
– 엔터티는 사람, 장소, 물건‘ 사건‘ 개염 등의 명사에 해당한다
– 엔터티는 업무상 관리가 멸요한 관심사에 해당한다
– 엔터티는 저장이 되기 위한 어떤 것 (Thing) 이다
2. 엔터티와 인스턴스에 대한 내용과 표기법
: 엔터티는 인스턴스의 집합
* 클래스는 여러개의 오브젝트를 포함하는 깡통. 엔터티와 인스턴스의 개념과 비슷하다.
3. 엔터티의 특징
가. 업무에서 필요로 하는 정보
: 엔터티 특정의 첫 번째는 반드시 시스템을 구축하고자 하는 업무에서필요로 하고 관리하고자 하는 정보여야 한다는 점이다
나. 식별이 가능해야함
: 식별자(UniqueIdentifier) 에 의해 식별이 가능해야 한다는 점이다.
다. 인스턴스의 집합
: 세 번째는 영속적으로 존재하는 인스턴스의 집합이 되어야 한다는점이다 엔터티의 특정 중 한 개가 아니라 “두 개 이상”이라는 집합개념은 매우 중요한 개념이다
* 인스턴스가 한 개 밖에 없는 회사, 병원 엔터티는 집합이 아니므로멘터티 성립이 안됨
라. 업무프로세스에 의해 이용
: 업무프로세스(BusinessProcess)가 그 엔터티를 반드시 이용해야 한다는 점이다
마. 속성을 포함
: 엔터티에는 반드시 속성(Attributes) 이 포함되어야 한다는 점이다 속성을 포함하지 않고 엔터티
의 이름만 가지고 있는 경우는 관계가 생략되어 있거나 업무 분석이 미진하여 속성정보가 누락되는 경우에
해당한다 또한 주식별자만 존재하고 일반속성은 전혀 없는 경우도 마찬가지로 적절한 엔터티라고 할 수 없다
단, 예외적으로 관계엔터티 (Associative Entity) 의경우는 주식별자 속성만 가지고 있어도 엔터티로 인정한다
바. 관계의 존재
: 엔터티는 다른 엔터티와 최소 한 개 이상의 관계가 존재해야 한다는것이다
* 단 ,데이터 모델링을하면서 관계를 생략하여 표현해야 하는 경우는 다음과 같은 통계성 엔터티 도출, 코드성 엔터티 도출, 시스템 처리시 내부 필요에 의한 엔터티 도출과같은 경우이다
4. 엔터티의 분류
가. 유무형에 따른 분류
1) 유형 엔터티 : 물리적인형태가 있고 안정적이며 지속적으로 활용되는 엔터티로 업무로부터 엔터티를 구분하기가 가장 용이하다.
2) 개념 엔터티 : 물리적인형태는 존재하지 않고 관리해야 할 개념적 정보로 구분이 되는 엔터티로 조직, 보험상품 등이 해당된다.
3) 사건 엔터티 : 업무를수행함에 따라 발생되는 엔터티. 주문, 청구, 미납 등이 해당된다.
나. 발생시점에 따른 분류
1) 기본/키엔터티 : 그 업무에 원래 존재하는 정보로서 다른 엔터티와 관계에 의해 생성되지 않고 독립적으로 생성이 가능하고 자신은타 엔터티의 부모의 역할을 하게된다. 다른 엔터티로부터 주식별자를 상속받지 않고 자신의 고유한 주식별자를가지게 된다.
2) 중심엔터티 : 기본엔터티로부터발생되고 그 업무에 있어서 중심적인 역할을 한다. 데이터의 양이 많이 발생되고 다른 엔터티와의 관계를통해 많은 행위 엔터티를 생성한다. 계약, 사고, 청구, 주문
3) 행위엔터티 : 두개 이상의 부모엔터티로부터 발생되고 자주 내용이 바뀌거나 데이터량이 증가된다. 분석초기 단계에서는 잘나타나지 않으며 상세 설계단계나 프로세스와 상관 모델링을 진행하면서 도출될 수 있다. 주문목록, 사원변경이력
5. 엔터티의 명명
1) 현업무업무에서 사용하는 용어를 사용한다.
2) 가능하면 약어를 사용하지 않는다.
3) 세 번재는 단수명사를 사용한다.
4) 모든엔터티에서 유일하게 이름이 부여되어야 한다.
5) 엔터티 생성의미대로 이름을 부여한다.
제 3 절 속성
1. 속성의 개념
:속성의 모델링 관점에서 정의” 업무에서 필요로 하는 인스턴스로 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위”
– 업무에서 필요로 한다.
– 의미상 더 이상 분리되지 않는다.
– 엔터티를 설명하고 인스턴스의 구성요소가 된다.
2. 엔터티, 인스턴스와속성, 속성값에 대한 내용과 표기법
가. 엔터티, 인스턴스, 속성, 속성값의 관계
– 한 개의 엔터티는 두 개 이상의 인스턴스의 집합이어야 한다.
– 한 개의 엔터티는 두 개 이상의 속성을 갖는다.
– 한 개의 속성은 한 개의 속성값을 갖는다.
나. 속성의 표기법
: 속성의 표기법은 엔터티 내에 이름을 포함하여 표현하면 된다.
3. 속성의 특징
– 엔터티와 마찬가지로 반드시 해당 업무에서 필요하고 관리하고자 하는정보이어야 한다.
– 정규화 이론에 근간하여 정해진 주식별자에 함수적 종속성을 가져야한다.
– 하나의 속성에는 한 개의 값만을 가진다. 하나의 속성에 여러개의 값이 있는 다중 값일 경우 별도의 엔터티를 이용하여 분리한다.
4. 속성의 분류
가. 속성의 특성에 따른 분류
1) 기본속성
: 기본 속성은 업무로부터 추출한 모든 속성이 여기에 해당하며 엔터티에가장 일반적이고 많은 속성을 차지한다.
2) 설계속성
:설계속성은 업무상 필요한 데이터 이외에 데이터 모델링을 위해, 업무를 규칙화하기 위해 속성을 새로 만들거나 변형하여 정의하는 속성이다.
3) 파생속성
: 파생속성은 다른 속성에 영향을 받아 발생하는 속성으로서 보통 계산된값들이 이에 해당된다.다른 속성에 영햐을 받기 때문에 프로세스 설계 시 데이터 정합성을 유지하기 위해유의해야 할 점이 많으며 가급적 파생속성을 적게 정의하는 것이 좋다.
나. 엔터티 구성방식에 따른 분류
– 엔터티를 식별할 수 있는 속성을PK속성, 다른 엔터티와의 관계에서 포함된 속성을 FK속성, 엔터티에 포함되어 있고 PK, FK 에 포함되지 않은 속성을 일반속성이라한다.
– 속성은 그안에 세부 의미를 쪼갤 수 있는지에 따라 단순형 혹은복합형으로 분류할 수 있다. (예 주소 -> 복합 , 시, 구, 동, 번지 -> 단순)
– 속성하나에 동일한 성질의 여러 개의 값이 나타나는 경우가 있다. 이 때 속성 하나에 한개의 갑을 가지는 경우를 단일값, 그리고 여러개의 값을 가지는 경우를 다중값 속성이라 한다.
5. 도메인
: 각 속성은 가질 수 있는 값의 범위가 있는데 이를 그 속성의 도메인이라한다.
6. 속성의 명명
– 해당업무에서 사용하는 이름을 부여한다.
– 서술식 속성명은 사용하지 않는다.
– 약어사용은 가급적 제한한다.
– 전체 데이터모델에서 유일성 확보하는 것이 좋다.
제 4 절 관계
1. 관계의 개념
가. 관계의 정의
– 사전적 정의로 상호 연관성이 있는 상태로 말할 수 있다.
– 데이터 모델에 정의로 보면 ,” 엔터티의 인스턴스 사이의 논리적인 연관성으로서 존재의 형태로서나 행위로서 서로에게 연관성이 부여된 상태”
나. 관계의 페어링
: 유의해야할 점은 관계는 엔터티 안에 인스턴스가 개별적으로 관계를가지는 것이고 이것의 집합을 관계로 표현한다는 것이다. 따라서 개별 인스턴스가 각각 다른 종류의 관계를가지고 있다면 두 엔터티 사이에 두 개 이상의 관계가 형성될 수 있다.
2. 관계의 분류
: 관계가 존재에 의한 관계와 행위에 의한 관계로 구분될 수 있는것은 관계를 연결함에 있어 어떤 목적으로 연결되었느냐에 따라 분류하기 때문이다.
(부서-사원 존재에 의한관계, 고객-주문 행위에 의한 관계)
3. 관계의 표기법
– 관계명 : 관계의 이름 (수동과 능동)
– 관계차수 : 1:1, 1:M,M:N
– 관계선택사양 : 필수고나계, 선택관계
가. 관계명
: 관계명은 엔터티가 관계에 참여하는 형태를 지칭한다. 각각의 관계는 두 개의 관계명을 가지고 있다. 또한 각각의 관계명에의해 두 가지의 관점으로 표현될 수 있다.
나. 관계차수
: 두 개의 엔터티간 관계에서 참여자의 수를 표현하는 것을 고나계차수라고한다.
다. 관계선택사양
: 참여하는 엔터티가 항상 참여하는지 아니면 참여할 수 도 있는지를나타내는 방법이 필수와 선택참여이다.
4. 관계의 정의 및 읽는 방법
가. 관계 체크사항
: 두개의 엔터티 사이에서 관계를 정의할 때 다음 사항을 체크해 보도록한다.
– 두 개의 엔터티 사이에 관심있는 연관규칙이 존재하는가?
– 두 개의 엔터티 사이에 정보의 조합이 발생되는가?
– 업무기술서, 장표에관계연결에 대한 규칙이 서술되어 있는가?
– 업무기술서, 장표에관계연결을 가능하게 하는 동사가 있는가?
나. 관계 읽기
: 데이터 모델을 읽는 방법은 먼저 관계계에 참여하는 기준 엔터티를하나 또는 각으로 읽고 대상 엔터티의 개수를 읽고 관계선택사양과 관계명을 읽도록 한다.
– 기준 엔터티를 한 개 또는 각각으로 읽는다.
– 대상 엔터티의 고나계 참여도 즉 개수 (하나, 하나 이상)를읽는다.
– 관계선택사양과 관계명을 읽는다.
제 5 절 식별자
1. 식별자 개념
: 엔터티는 인스턴스들의 집하이라고 하였다. 여러 개의 집합체를 담고 있는 하나의 통에서 각각을 구분할 수 있는 논리적인 이름이 있어야 한다. 이 구분자를 식별자 라고 한다.
2. 식별자의 특징
: 주식별자인지 아니면 외부식별자인지 등에 따라 특성이 다소 차이가있다. 주식별자일 경우 다음과 같은 특징을 갖는다.
– 유일성 : 주식별자에의해 엔터티내에 모든 인스턴스들이 유일하게 구분 되어야 한다.
– 최소성 : 주식별자를구성하는 속성의 수는 유일성을 만족하는 최소의 수가 되어야 한다.
– 불변성 : 지정된 주식별자의값은 자주 변한지 않는 것이어야 한다.
– 존재성 : 주식별자가지정이 되면 반드시 값이 들어와야 한다.
3. 식별자 분류 및 표기법
가. 식별자 분류
– 대표성 여부 : 주식별자, 보조 식별자 (엔터티 내에서 각 어커런스를 구분할 수 있는 구분자이나대표성에 따라 참조관계를 연결 할 수 있고 없고의 차이)
– 스스로 생성여부 : 내부식별자, 외부식별자 ( 내부에서 만들어 지고, 타 언터티와 가녜를 토해 타 언터티로부터 받아오는 식별자
– 속성의 수 : 단일식별자, 복합실 식별자(속성의 개수에 따라 하시 바라.
– 대체여부 : 업무의의해 만들어 지는 식별자
4. 주식별자 도출 기준
: 데이터 모델링 작업에서 중요한 작업 중의 하나가 주식별자 도출작업이다. 주식별자를 도출하기 위한 기준을 정리하면 다음과 같다.
– 해당 업무에서 자주 이용되는 속성을 주식별자로 지정한다.
– 명칭, 내역 등과 같이이름으로 기술되는 것들은 가능하면 주식별자로 지정하지 않는다.
– 복합으로 주식별자로 구성할 경우 너무 많은 속성이 포함되지 않도록한다.
가. 해당 업무에서 자주 이용되는 속성을 주식별자로 지정하도록 함.
나. 명칭, 내역 등과같이 이름으로 기술되는 것은 피함
: 부서명은 유일 할 수 있으나where 조건절에 항상 쓰일 수 있으므로 부서코드를 부여하여 사용하는게 효율적이다.
다. 속성의 수가 많아지지 않도록 함
5. 식별자관계와 비식별자관계에 따른 식별자.
가. 식별자관계와 비식별자 관계의 결정
: 외부식별자는 자기 자신의 엔터티에서 필요한 속성이 아니라 다른엔터티와의 관계를 통해 자식 쪽에 엔터티에 생성되는 속성을 외부식별자라 한다.
나. 식별자 관계
: 부모로부터 받은 식별자를 자식엔터티의 주식별자로 이용하는 경우는 Null값이 오면 안되므로 반드시 부모엔터티가 생성되어야 자기 자신의 엔터티가 생성되는 경우이다. 자식엔터티의 주식별자로 부모의 주식별자가 상속이 되는 경우를 식별자 관계라고 지칭한다.
다. 비식별자관계
: 부모엔터티로부터 속성을 받았지만 자식엔터티의 주식별자로 사용하지않고 일반적인 속서으로만 사용하는 경우를 비식별자 관계라고 한다.
1) 자식엔터티에서 받은 속성이 반드시 필수가 아니어도 무방하기 때문에부모 없는 자식이 생성될 수 있는 경우이다.
2) 엔터티별로 데이터의 생명주기를 다르게 관리할 경우이다. 예를 들어 부모엔터티에 인스턴스가 자식의 엔터티와 관계를 가지고 있었지만 자식만 남겨두고 먼저 소멸될 수 있는경우가 이에 해당된다.이에 대한 방안으로 무리데이터베이스 생성시 외부키를 연결하지 앟는 임시적인 방법을사용하기도 하지만 데이터 모델상에서 관게를 비식별자고나계로 조정하는 것이 가장 좋은 방법이다.
3) 여러 개의 엔터티가 하나의 엔터티로 통합되어 표현되었는데 각각의엔터티가 별도의 관계를 가질 때이며 이에 해당도니다.
4) 자식엔터티에 주식별자로 사용하여도 되지만 자식엔터티에서 별도의주식별자를 생성하는 것이 더 유리하다고 판단될 때 비식별자 관계에 의한 외부식별자로 표현한다.
라. 식별자 관계로만 설정할 경우의 문제점
: 부여받는 속성이 많을 경우 너무 복잡해 진다.
마. 비식별자 관계로만 설정할 경우의 문제점
: 간단한 조회 쿼리도 부모 테이블에 조인하기 위해서 몇번을 조인해야하는경우가 발생
바. 식별자관계와 비식별자관계 모델링
1) 비식별자관계 선택 프로세스
관계분석 -> 관계의강/약분석 ->자식 테이블 독립 PK필요 ->SQL복잡도 증가 개발생산성저하
약한|관계 독립|PK구성 PK속성|단순화
##### 비식별자 관계 설정 고려 #####
2)식별자와 비식별자관계 비교
항목 식별자관계 비식별자관계 목적 강한 연결관계 표현 약한 연결관계 표현 자식 주식별자 영향 자식 주 식별자의 구성에 포함됨 자식 일반 속성에 포함됨 표기법 실선 표현 점선 표현 연결 고려사항 – 반드시 부모엔터티 종속 – 자식 주식별자구성에 부모 주식별자포함 필요 – 상속받은 주식별자속성을 타 엔터티에 이전 필요 – 약한 종속관계 – 자식 주식별자구성을 독립적으로 구성 – 자식 주식별자구성에 부모 주식별자 부분 필요 – 상속받은 주식별자속성을 타 엔터티에 차단 필요 – 부모쪽의 관계참여가 선택관계
3) 식별자와 비식별자를 적용한 데이터 모델
Entity와 Table
반응형
Jpa를 공부하다보면 제일 먼저 Entity를 만나볼 수 있습니다.
이걸 보고 있으면 객체이면서 테이블 같은 오묘한 기분을 느낄 수 있습니다.
이는 사실 JPA의 특징의 영속성과 큰 연관이 있습니다.
영속성
영속성이라는 것은 한 객체가 생성 작업이 종료 되었음에도 지속적으로 존재하는 상태라는 것을 말합니다.
물론 억지로 close같은 걸 이용하거나 프로그램을 강제로 종료 시킨다면 소멸 되겠지만
그렇지 않으면 웬만하면 죽지 않습니다.
그게 바로 영속성입니다. 근데 어째서 JPA에서는 영속성이라는 용어를 사용하면서 관리를 하는 걸까요?
그건 바로 객체를 이용해서 테이블을 생성하고 이용하고 싶기 때문이라고 생각합니다.
물론 마이바티스 처럼 자바에서 쿼리를 작성해서 DB에 연동시키는 게 더 좋을거라 생각할지도 모릅니다.
어떻게 보면 그렇게 하는것이 더 개발 속도 측면에서 더 빠르다고 느낄 지도 모릅니다.
왜냐하면 쿼리만 작성하면 되기 때문이죠.
하지만 생각해보세요. 영속성이라는 것을 사용하게 되면 어찌되었든 테이블이 아니라 다른 곳에 데이터를 저장을 해야 됩니다.
그래야 JPA가 그 데이터를 조작할 수 있기 때문이죠. 물론 마이바티스보다 1가지 이상의 작업을 더 해야되기 때문에 간단한 쿼리를 작성을
해야 된다면 마이바티스가 성능이 더 좋을지도 모릅니다.
하지만 1이상의 작업을 더 해야된다는 이야기는 어떻게 보면 잘 동작하는 공장과 같다고 생각이 듭니다.
인형 하나를 만든다고 가정했을때, 한명이 만드는 것이 여러명이 함께 만드는 것보다 더 빠를 수 있습니다. 하지만 인형이 하나가 아니라 여러개 라면 얘기는 달라집니다. 공장에서는 이러한 환경이 구축이 되었기 때문에 추가적으로 인형을 하나를 더 만드는 것은 일도 아니게 되어집니다. 물론 이 비유는 JPA와 전혀 상관이 없는 비유입니다. 제가 말하고 싶은 점은 이러한 환경을 미리 구축을 해놓은 다면 쿼리 하나를 만들때는 타 제품보다 느려도 쿼리가 그 이상이라면 더 효율적이지 않을까요? 물론 빠르다고는 말 못하겠습니다. 왜냐하면 제가 이에대한 전문가가 아니기 때문이죠.
이에 대해서는 더 할 말이 많지만 이에 대한 주제가 아니기 때문에 넘어가도록 하죠.
아무튼 JPA는 객체를 만들게 되면 @Entity라는 어노테이션을 붙이게 되면 JPA는 이 객체를 이제부터 JPA가 관리를 하겠다고 선언합니다. 그러면 언제든지 이 객체를 언제든지 영속화를 시킬 수 있습니다.
@Entity public class Hello { }
제일 먼제 이 객체에 꼭 필요한 녀석이 있습니다. 그건 바로 Id값입니다. Id값은 db세계에서는 pk라고 부른다고 합니다.
아무튼 실 db세계에서는 pk값이 반 필수 지만 이쪽 세계에서 몸담고 있는 JPA는 이 값을 강제적으로 pk를 지정하게 했습니다.
이로써 이 객체로 만들어진 db는 pk값을 가진다는 사실을 알 수 있습니다.
여기서 궁금한게 생겼습니다.
과연 pk를 입력하지 않는 Entity는 어떤 에러를 던질까? 당연한 이야기 겠지만 일단은 컴파일에러를 던져주겠죠?
바로 No identifier specified for entity라는 에러를 던져줍니다. 이말은 식별자를 넣으라는 뜻입니다.
일반적으로 식별자는 Long을 많이 이용합니다. 왜냐하면 이게 관행이면서 과거에 엄청난 사건들이 있었기 때문이라 생각합니다.
아니면 Inteager,String등을 사용해두 됩니다. 근데 어째서 int같은 primitive 타입을 사용하지 않고 Object 타입을 사용하는 이유는 어디까지나 null때문입니다. 객체가 0인건 말이 되지 않죠. 객체가 없는건 말이되도..
만약, 물론 직접 ID값을 입력해도 되겠지만
mysql의 auto increament처럼 자동으로 값을 지정하는게 있으면 좋을 것 같습니다.
@Entity public class Hello { @Id @GeneratedValue private Long id; }
이렇게 하면 값을 자동으로 1씩 증가됨을 알 수 잇습니다.
db마다 값을 올리는 방식이 조금씩 다릅니다. 이러한 점을 해결하기 위해 JPA에서는 총 3가지 방식으로 이를 제공하고 있습니다.
1. @GeneratedValue (strategy =IDENTITY)
2. @GeneratedValue(strategy=SEQUENCE)
3. @GeneratedValue(strategy=TABLE)
위에서 부터 하나씩 설명하자면, 식별자 전략으로 그냥 1씩 증가시키는 방법을 말합니다.
근데 이 방법은 약간의 문제가 있습니다.
일반적으로 jpa는 commit 할때 db에 반영이 되어집니다. 하지만 이 방법은 애초에 객체에서 1씩 증가는 것이 아니라 테이블이 1씩 증가하는 형태이기 때문에 영속화 상태가 될때 값을 알 고 있어야 됩니다. 근데 commit될때 id값이 반영이 되어집니다.
여기서 이 방식에 문제가 발생했습니다. 그러면 이 방법은 사용하면 안되는 것일까요? JPA에서는 이 방식에 대해서는 영속화상태로 만들때 insert쿼리를 날려버립니다. 즉, flush를 쓴다는 말이죠.
다행스럽게도 성능적인 큰 이슈가 없다고 합니다. JPA 화이팅!
어떻게 보면 2번째 방식과 3번째 방식은 유사점이 굉장히 많습니다. 다른점은 테이블을 만들어서 사용하냐 아니냐에 차이라 생각합니다.
3번째 방식은 2번째 방식을 흉내낸 방식이기 때문에 성능이 굉장이 떨어집니다.
이에 대해서는 더 말할 기회가 있다면 다음에 하도록 하죠. 왜냐하면 이제 그만 하고 싶기 때문이죠.
(네 사실 제가 설명하기 어려워서 그래요 )
아무튼 JPA는 이렇게 3가지 방식을 제공하고 있고 이게 가능한 이유는 방언때문입니다.
그러면 이렇게 id값을 만들었다면, 데이터를 넣어야져.
데이터는 어떠한 방식이든 넣으면 됩니다.
심지어 get, set 없이
@Id Long id; String name;
이렇게 만들어도 insert쿼리가 나가긴 합니다. 물론 이 방식은 캡슐화에 맞지 않기때문에 사용은 안하는게. 좋을 것 같습니다.
굳이 get/set이 아니여도 객체에 값을 넣는 어떠한 방법이라면 뭐든지 가능합니다.
진짜 final은 불가능한걸까요?
final로 하면 값이 들어가지 않는다는 이야기가 있던데 생성자를 이용하면 가능할것 같은데..
그거 제가 해보겠습니다.
@Id private final Long id; private final String name; public Members(Long id, String name) { this.id = id; this.name = name; }
Hibernate:
/* insert helloJava.Members
*/ insert
into
Members
(name, id)
values
(?, ?)
이렇게 하면 값이 들어가지는 군요. 여기에다 @Builder를 붙이면 생각만해도 기분이 좋아집니다.
이제 데이터를 각자의 입맛에 맞게 맞춰서 만들면 되겠습니다.!
반응형
So you have finished reading the 엔티티 테이블 차이 topic article, if you find this article useful, please share it. Thank you very much. See more: 데이터베이스 테이블, JPA @Entity create table, DB 엔티티 란, 엔티티정의서, JPA table schema, JPA view 테이블, JPA 다른 스키마, 데이터베이스 용어