
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 웹 페이지 html 추출 on Google, you do not find the information you need! Here are the best content compiled and compiled by the Toplist.maxfit.vn team, along with other related topics such as: 웹 페이지 html 추출 웹페이지 긁어오기 프로그램, 웹사이트 통째로 가져오기, javascript 웹 페이지 긁어오기, R html 추출, 자바 스크립트 웹 페이지 긁어오기, 웹페이지 특정 부분 가져 오기, 웹페이지 텍스트 긁어오기, HTML 긁기
먼저 첫번째 방법입니다. 우클릭을 하고 페이지 소스보기를 클릭합니다. html 소스코드가 새 탭에 출력될 것입니다. Ctrl+F를 누르고 ‘김미경의 리부트’를 클릭하면 아래와 같이 html 소스코드 형태로 입력되어 있는 것을 확인할 수 있습니다.
[도구 R로 하는 크롤링] 2. 웹페이지의 html 소스코드 보는 법
- Article author: statools.tistory.com
- Reviews from users: 30160
 Ratings
Ratings - Top rated: 3.2
- Lowest rated: 1
- Summary of article content: Articles about [도구 R로 하는 크롤링] 2. 웹페이지의 html 소스코드 보는 법 Updating …
- Most searched keywords: Whether you are looking for [도구 R로 하는 크롤링] 2. 웹페이지의 html 소스코드 보는 법 Updating 도구 R로 하는 크롤링 2. 웹페이지의 html 소스코드 보는 법 교보문고의 베스트셀러 순위 중 1위를 크롤링으로 가져오고 싶다고 해봅시다. 먼저 교보문고 홈페이지에 들어갑시다. 메뉴에 보시면 ‘베스트’ 라는..
- Table of Contents:
태그
관련글
댓글0
전체 방문자
최근댓글
태그
티스토리툴바
![[도구 R로 하는 크롤링] 2. 웹페이지의 html 소스코드 보는 법](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F99A6D24E5F1BE79409)
html 소스 가져오기 & CSS 파일 가져오기
- Article author: hyeon-9405.tistory.com
- Reviews from users: 38127 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about html 소스 가져오기 & CSS 파일 가져오기 오늘은 html 하고 css 파일을 가져와 보는 시간 입니다. 원하는 사이트 아무곳이나 집어서 저는 네이버를 예로 들도록 하겠습니다. …
- Most searched keywords: Whether you are looking for html 소스 가져오기 & CSS 파일 가져오기 오늘은 html 하고 css 파일을 가져와 보는 시간 입니다. 원하는 사이트 아무곳이나 집어서 저는 네이버를 예로 들도록 하겠습니다. 호성동쎕쎕이 님의 블로그입니다.
- Table of Contents:

크롬 브라우저 웹 페이지 소스 보기, HTML 디자인 확인하기
- Article author: mainia.tistory.com
- Reviews from users: 40115 Ratings
- Top rated: 3.8
- Lowest rated: 1
- Summary of article content: Articles about 크롬 브라우저 웹 페이지 소스 보기, HTML 디자인 확인하기 다른 사이트의 제작 기법을 보고 싶다면 HTML 과 Javascript, CSS 소스를 볼 수 있어야 합니다. 크롬은 웹페이지 소스를 분석하는데 도움을 주는 … …
- Most searched keywords: Whether you are looking for 크롬 브라우저 웹 페이지 소스 보기, HTML 디자인 확인하기 다른 사이트의 제작 기법을 보고 싶다면 HTML 과 Javascript, CSS 소스를 볼 수 있어야 합니다. 크롬은 웹페이지 소스를 분석하는데 도움을 주는 … 다른 사이트의 제작 기법을 보고 싶다면 HTML 과 Javascript, CSS 소스를 볼 수 있어야 합니다. 크롬은 웹페이지 소스를 분석하는데 도움을 주는 개발자 도구를 제공하고 있습니다. 개발자 도구는 단순히 소스만..IT 관련 정보수록컴퓨터,윈도우,엑셀,안드로이드,워드,자바,한글,ITcomputer,windows,Internet,excel,word
- Table of Contents:
크롬 브라우저 웹 페이지 소스 보기 HTML 디자인 확인하기
티스토리툴바

파이썬 코딩 도장: 46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기
- Article author: dojang.io
- Reviews from users: 19825 Ratings
- Top rated: 4.0
- Lowest rated: 1
- Summary of article content: Articles about 파이썬 코딩 도장: 46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기 참고로 기상청 웹 사이트는 시간이 지나면 개편을 하므로 웹 페이지의 HTML 구조도 바뀌게 됩니다. 특히 파이썬 코딩 도장 책이 나온 뒤에 기상청 웹 사이트가 개편 … …
- Most searched keywords: Whether you are looking for 파이썬 코딩 도장: 46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기 참고로 기상청 웹 사이트는 시간이 지나면 개편을 하므로 웹 페이지의 HTML 구조도 바뀌게 됩니다. 특히 파이썬 코딩 도장 책이 나온 뒤에 기상청 웹 사이트가 개편 … 코딩 도장, Coding Dojang, 파이썬 코딩 도장: 46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기코딩 도장: 따라하기, 연습하기, 심사하기로 배우는 프로그래밍 철저입문
- Table of Contents:
463 웹 페이지의 HTML을 가져와서 파일로 저장하기
내비게이션
파이썬으로 웹 페이지에서 정보 추출하기(웹스크레이핑, 웹크롤링)/Request와 Beautifulsoup 이용하기
- Article author: codealone.tistory.com
- Reviews from users: 14535 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about 파이썬으로 웹 페이지에서 정보 추출하기(웹스크레이핑, 웹크롤링)/Request와 Beautifulsoup 이용하기 그리고 beautifulsoup는 requests로 불러온 HTML 소스를 분석(parsing)하고, 필요한 정보를 추출하는 데 쓴다. 둘다 내장 라이브러리가 아니므로 pip … …
- Most searched keywords: Whether you are looking for 파이썬으로 웹 페이지에서 정보 추출하기(웹스크레이핑, 웹크롤링)/Request와 Beautifulsoup 이용하기 그리고 beautifulsoup는 requests로 불러온 HTML 소스를 분석(parsing)하고, 필요한 정보를 추출하는 데 쓴다. 둘다 내장 라이브러리가 아니므로 pip … 서론 파이썬 입문 콘텐츠에서 가장 흔히 보이는 것이 바로 웹페이지에 게시된 정보들을 추출하여 활용하는 웹스크레이핑 방법인 것 같다. 이미 이에 대해 잘 설명하고 있는 수많은 자료들이 있으나, 필자 스스로..
- Table of Contents:
서론
본론
마무리
태그
관련글
댓글0

IMPORTHTML: 웹페이지에서 표 또는 리스트를 추출 – 생산성 앱 활용 팁
- Article author: wikidocs.net
- Reviews from users: 24591 Ratings
- Top rated: 3.3
- Lowest rated: 1
- Summary of article content: Articles about IMPORTHTML: 웹페이지에서 표 또는 리스트를 추출 – 생산성 앱 활용 팁 HTML 표(table) 또는 목록(list) 데이터만 필요하다면 Google Sheets(스프레드시트)의 importhtml() 함수를 이용해 간단히 얻어올 수 있다. 위키백과의 … …
- Most searched keywords: Whether you are looking for IMPORTHTML: 웹페이지에서 표 또는 리스트를 추출 – 생산성 앱 활용 팁 HTML 표(table) 또는 목록(list) 데이터만 필요하다면 Google Sheets(스프레드시트)의 importhtml() 함수를 이용해 간단히 얻어올 수 있다. 위키백과의 … 온라인 책을 제작 공유하는 플랫폼 서비스
- Table of Contents:

웹 페이지의 HTML을 가져와서 파일로 저장하기
- Article author: velog.io
- Reviews from users: 37503 Ratings
- Top rated: 4.1
- Lowest rated: 1
- Summary of article content: Articles about 웹 페이지의 HTML을 가져와서 파일로 저장하기 명이 ‘table_develop3’인 table 태그를 가져오기로 한다. HTML 파싱 텍스트 형태의 HTML 코드를 분석해서 객체로 만든 뒤 검색하거나 편집할 수 … …
- Most searched keywords: Whether you are looking for 웹 페이지의 HTML을 가져와서 파일로 저장하기 명이 ‘table_develop3’인 table 태그를 가져오기로 한다. HTML 파싱 텍스트 형태의 HTML 코드를 분석해서 객체로 만든 뒤 검색하거나 편집할 수 … 파이썬 코딩 도장 46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기
- Table of Contents:
Python으로 웹 스크래퍼 만들기
가져올 HTML 확인하기
데이터를 csv 파일에 저장하기

[춘식이의 코드이야기] 10분만에 따라하는 웹사이트 긁어오기
- Article author: codenamu.org
- Reviews from users: 49571 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about [춘식이의 코드이야기] 10분만에 따라하는 웹사이트 긁어오기 자바스크립트를 활용한 ’10만에 따라하는 HTML 긁어오기’. 굳이 10분만에 따라할 수 있는 것은 HTML을 가져오기 위한 가장 기본적인 기능만을 만들어볼 … …
- Most searched keywords: Whether you are looking for [춘식이의 코드이야기] 10분만에 따라하는 웹사이트 긁어오기 자바스크립트를 활용한 ’10만에 따라하는 HTML 긁어오기’. 굳이 10분만에 따라할 수 있는 것은 HTML을 가져오기 위한 가장 기본적인 기능만을 만들어볼 … 코드나무는 공공정보 개방은 정부의 투명성을 높이고 새로운 부가가치를 만들어 낼 뿐만 아니라 무엇보다도 시민들의 참여를 통해서 새로운 혁신, 새로운 공공가치의 창조를 이끌어낼수 있다고 믿습니다. 코드나무와 같이 시민들의 지속적이고 자발적인 참여가 시민들의 참여를 끌어내고 실현시킬 수 있는 플랫폼을 구축하고 적극적으로 참여할 수 있는 문화를 바꿀 수 있다고 믿습니다. 코드나무는 정부를 탓하기 보다는 우리가 직접 보여줄 수 있는 프로젝트를 통해서 시민과 정부가 협력할 수 있는 모델을 만들고자 합니다.
- Table of Contents:
HTTrack 웹사이트 소스 가져오기 : 네이버 블로그
- Article author: blog.naver.com
- Reviews from users: 3593 Ratings
- Top rated: 4.8
- Lowest rated: 1
- Summary of article content: Articles about HTTrack 웹사이트 소스 가져오기 : 네이버 블로그 우리가 브라우저에서 보는 소스는 기본적으로 html, javascript, css, 그리고 기타 컨텐츠파일로 이루어져 있습니다. 물론 소스 자체는 웹 서버에 있고 … …
- Most searched keywords: Whether you are looking for HTTrack 웹사이트 소스 가져오기 : 네이버 블로그 우리가 브라우저에서 보는 소스는 기본적으로 html, javascript, css, 그리고 기타 컨텐츠파일로 이루어져 있습니다. 물론 소스 자체는 웹 서버에 있고 …
- Table of Contents:
blog
악성코드가 포함되어 있는 파일입니다
작성자 이외의 방문자에게는 이용이 제한되었습니다
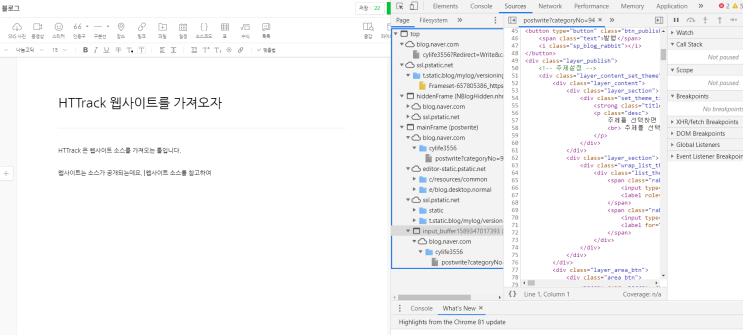
HTTrack 웹사이트 소스 가져오기 : 네이버 블로그
- Article author: kldp.org
- Reviews from users: 18942 Ratings
- Top rated: 3.3
- Lowest rated: 1
- Summary of article content: Articles about HTTrack 웹사이트 소스 가져오기 : 네이버 블로그 그래서 생각한 것이 홈페이지를 읽을 때 보이는 부분의 html 소스만을 추출해 주는 … 파이어폭스에 웹 개발자 기능이 있는데 한번 참고해 보세요. …
- Most searched keywords: Whether you are looking for HTTrack 웹사이트 소스 가져오기 : 네이버 블로그 그래서 생각한 것이 홈페이지를 읽을 때 보이는 부분의 html 소스만을 추출해 주는 … 파이어폭스에 웹 개발자 기능이 있는데 한번 참고해 보세요.
- Table of Contents:
blog
악성코드가 포함되어 있는 파일입니다
작성자 이외의 방문자에게는 이용이 제한되었습니다
See more articles in the same category here: toplist.maxfit.vn/blog.
[도구 R로 하는 크롤링] 2. 웹페이지의 html 소스코드 보는 법
반응형
도구 R로 하는 크롤링
2. 웹페이지의 html 소스코드 보는 법
교보문고의 베스트셀러 순위 중 1위를 크롤링으로 가져오고 싶다고 해봅시다. 먼저 교보문고 홈페이지에 들어갑시다. 메뉴에 보시면 ‘베스트’ 라는 버튼이 있습니다. 이 버튼을 클릭하면 분야종합베스트 화면으로 이동합니다.
김미경의 리부트가 현재 1위입니다.
우리가 가져오고 싶은 것은 ‘김미경의 리부트’라는 글자입니다. 우리가 인터넷에서 보고 있는 모든 글자들은 html 이라는 언어로 되어 있습니다. 나중에 크롤링을 통해 가져올 정보도 html 코드에서 가져오는 것입니다. 어떤 웹페이지의 화면을 구성하는 html 코드를 확인하는 방법은 두가지가 있습니다. 오늘 그 방법을 알아볼 것입니다.
먼저 첫번째 방법입니다. 우클릭을 하고 페이지 소스보기를 클릭합니다. html 소스코드가 새 탭에 출력될 것입니다. Ctrl+F를 누르고 ‘김미경의 리부트’를 클릭하면 아래와 같이 html 소스코드 형태로 입력되어 있는 것을 확인할 수 있습니다. (여러분이 이 글을 읽으실 때는 다른 책이 1위를 하고 있을 확률이 높은데, 해당 책으로 검색하시면 됩니다.)
새로 열리 탭의 위쪽에 보시면 URL 을 알 수 있습니다. 이 URL에 접근하여 화면을 구성하고 있는 html 소스코드를 가져올 수 있습니다. 웹페이지 화면에 나타나는 정보는 위와 같은 html 소스 코드 형태로 가져옵니다. 이후에는 html 소스 코드의 ‘형식’을 이용하여 우리가 원하는 정보를 추출해야 합니다.
이번에는 html 소스코드를 확인하는 두번째 방법을 설명드리겠습니다. 다시 교보문고 ‘종합 주간 베스트’ 화면으로 가서 우클릭을 하고 ‘검사’를 클릭합니다. 새 탭이 생기지 않고, 오른쪽에(혹은 아래 쪽에) 창이 하나 열립니다. 이 창을 구글개발자도구라고 합니다. 창의 위치를 바꾸는 방법은 오른쪽위에 x 표시 왼쪽에 있는 점세개를 클릭하고 Dock side 에서 원하는 위치를 선택해주면 됩니다.
Elements 탭이 기본으로 선택되어 있고, html 코드가 보입니다.
첫번째 방법의 소스코드와 다른 점은 html 의 구조를 한눈에 볼 수 있다는 것입니다. 아주 유용한 기능이 하나 있는데요. Elements 탭에서 왼쪽으로 두칸을 가면 화면에 마우스커서가 올라가있는 버튼이 있습니다. 이 버튼을 한번 클릭하고, 화면에 원하는 부분을 클릭하면, 그 부분이 html 코드 상에서 어느 부분에 있는지를 알려줍니다.
웹크롤링은 웹페이지를 구성하는 HTML 코드에서 우리가 원하는 텍스트를 가져오는 것입니다. 웹크롤링의 절차는 아래와 같습니다.
1) 어떤 정보를 가져올지 정합니다.
2) 크롬개발자도구를 이용하여 우리가 가져오기 원하는 정보에 접근합니다.
3) html 코드의 구조를 이용하여 원하는 정보를 어떤 로직으로 가져올지 정합니다.
4) R을 이용하여 해당 URL 에 있는 html 코드를 전부 불러옵니다.
5) 3에서 정한 로직을 이용하여 html 코드에서 원하는 정보만 추출합니다.
다음시간에 위 절차를 실제로 적용해봅시다.
반응형
크롬 브라우저 웹 페이지 소스 보기, HTML 디자인 확인하기
반응형
다른 사이트의 제작 기법을 보고 싶다면 HTML 과 Javascript, CSS 소스를 볼 수 있어야 합니다. 크롬은 웹페이지 소스를 분석하는데 도움을 주는 개발자 도구를 제공하고 있습니다. 개발자 도구는 단순히 소스만 보여주는 것이 아니라 화면을 분석하는데 필요한 여러 기능들을 지원합니다. 다른 어떤 개발툴보다 뛰어나기 때문에 웹 페이지 분석할 때 항상 개발자 도구를 사용하고 있습니다.
◎ 웹 페이지 소스 보기
▼ 간단하게 소스를 확인하는 방법은 다른 브라우저와 동일합니다. 웹 페이지에서 오른쪽 마우스를 누르면 나타나는 페이지 소스 보기 메뉴를 이용하는 것입니다. 바로 실행하는 단축키는 Ctrl + U 입니다.
▼ 페이지 소스보기 이후에는 HTML 소스가 있는 새로운 탭이 나타납니다. 단, 오른쪽 마우스를 누르면 나타나는 빠른 실행 메뉴 보기가 차단된 사이트는 나타나지 않습니다. 이런 경우에는 브라우저에서 제공하는 개발자 도구를 이용해야 합니다.
◎ 개발자 도구로 소스 분석하기
▼ 두 번째는 개발자 도구를 통해서 확인하는 방법입니다. 주로 소스를 분석하기 위한 도구로 오른쪽 상단에 더보기 > 도구 더보기 > 개발자 도구 메뉴를 클릭해서 창을 띄울 수 있습니다. 단축키는 Ctrl + Shift + I 혹은 F12 입니다.
▼ F12 단축키를 눌러 개발자 도구를 띄우면 화면 하단이나 양 옆에 브라우저 내에 창이 나타납니다. 위치는 사용자가 정할 수 있으며, 새로운 창으로 띄울 수도 있습니다. 소스는 Elements 탭에서 볼 수 있습니다.
▼ Elements 탭에서 오른쪽 영역의 창에는 디자인 소스인 CSS 코드를 보여줍니다. 특정 태그에 적용된 디자인 코드로 상단 파일 링크를 클릭하면 실제 소스 파일로 이동할 수 있습니다.
▼ CSS 소스가 들어간 실제 파일의 내용을 보고 싶다면 Sources 탭으로 이동해야 합니다.
◎ 사용자가 원하는 특정 위치의 소스 보기
▼ 개발자 도구의 유용한 기능 중 하나는 사용자가 특정 웹 페이지 영역의 소스를 마우스 클릭 한번으로 찾아볼 수 있다는 것입니다. 개발자 도구 왼쪽 상단 끝에 화살표 아이콘을 클릭해서 파란색으로 전환합니다.
▼ 다음 웹 페이지의 특정 영역에서 소스를 보고 싶은 곳이 있다면 마우스로 클릭합니다. 개발자 도구에서는 화면에서 마우스로 선택한 영역의 소스로 이동한 후 사용자가 구분하기 쉽도록 회색으로 블록 처리합니다.
반응형
파이썬 코딩 도장: 46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기
이제 기상청 웹 사이트에서 도시별 현재날씨 페이지의 HTML을 가져와보겠습니다. 웹 브라우저를 실행하고 다음 주소로 이동합니다.
도시별 현재날씨 > 지상관측자료 > 관측자료 > 날씨 > 기상청
http://www.kma.go.kr/weather/observation/currentweather.jsp
▼ 그림 46-15 기상청 도시별 현재날씨
웹 페이지를 보면 도시별 기상 데이터가 나옵니다. 많은 데이터가 표시되지만 우리는 이 웹 페이지에서 지점, 기온(현재기온), 습도만 가져오겠습니다.
참고로 기상청 웹 사이트는 시간이 지나면 개편을 하므로 웹 페이지의 HTML 구조도 바뀌게 됩니다. 특히 파이썬 코딩 도장 책이 나온 뒤에 기상청 웹 사이트가 개편되었을 경우에는 책 내용대로 실습을 할 수 없게 됩니다. 따라서 이번 유닛에서는 원활한 실습을 위해 도시별 현재날씨 페이지를 복사해서 올려놓은 Bitbucket 주소를 사용하겠습니다.
46.3.1 가져올 HTML 확인하기
그럼 웹 브라우저에서 다음 주소로 이동하고, F12를 눌러서 개발자 도구를 표시합니다(여기서는 크롬을 사용하겠습니다). 그리고 왼쪽 아래 커서 버튼을 클릭(Ctrl+Shift+C)한 뒤 현재날씨 표에서 지점을 클릭합니다.
Bitbucket 도시별 현재날씨 페이지
https://pythondojang.bitbucket.io/weather/observation/currentweather.html
▼ 그림 46-16 개발자 도구에서 지점 선택
참고 | 웹 페이지가 열리지 않는다면? 만약 위 웹 페이지가 열리지 않는다면 HTML을 가져오는 과정은 생략하고, GitHub 저장소의 Unit 46/weather.txt 파일을 이용하여 ‘46.4 데이터로 그래프 그리기’ 실습을 진행하기 바랍니다.
이제 지점에 해당하는 HTML 코드가 표시됩니다. 여기서 스크롤을 위쪽으로 조금 올린 뒤
C : \ Users \ dojang \ Anaconda3 \ python . exe – m notebook — notebook – dir C : \ project
주피터 노트북에서 새 노트북을 만든 뒤 코드 셀에 다음 내용을 입력합니다.
weather.ipynb
import requests # 웹 페이지의 HTML을 가져오는 모듈 from bs4 import BeautifulSoup # HTML을 파싱하는 모듈 # 웹 페이지를 가져온 뒤 BeautifulSoup 객체로 만듦 response = requests . get ( ‘https://pythondojang.bitbucket.io/weather/observation/currentweather.html’ ) soup = BeautifulSoup ( response . content , ‘html.parser’ ) table = soup . find ( ‘table’ , { ‘class’ : ‘table_develop3’ }) #
을 찾음 data = [] # 데이터를 저장할 리스트 생성 for tr in table . find_all ( ‘tr’ ): # 모든
태그를 찾아서 반복(각 지점의 데이터를 가져옴) tds = list ( tr . find_all ( ‘td’ )) # 모든 태그를 찾아서 리스트로 만듦 # (각 날씨 값을 리스트로 만듦) for td in tds : # 태그 리스트 반복(각 날씨 값을 가져옴) if td . find ( ‘a’ ): # 안에 태그가 있으면(지점인지 확인) point = td . find ( ‘a’ ) . text # 태그 안에서 지점을 가져옴 temperature = tds [ 5 ] . text # 태그 리스트의 여섯 번째(인덱스 5)에서 기온을 가져옴 humidity = tds [ 9 ] . text # 태그 리스트의 열 번째(인덱스 9)에서 습도를 가져옴 data . append ([ point , temperature , humidity ]) # data 리스트에 지점, 기온, 습도를 추가 data # data 표시. 주피터 노트북에서는 print를 사용하지 않아도 변수의 값이 표시됨 실행을 해보면 Out [1]: 부분에 data의 값이 표시됩니다. 여기서 Out [1]:은 In [1]:의 출력이라는 뜻입니다.
▼ 그림 46-18 웹 페이지에서 가져온 데이터 표시
46.3.3 HTML의 데이터를 가져오는 방식 알아보기
그럼 지점, 기온(현재기온), 습도 값을 어떻게 가져오는지 알아보겠습니다. 웹 브라우저의 개발자 모드에서 왼쪽 아래 커서 버튼을 클릭(Ctrl+Shift+C)한 뒤 서울을 클릭합니다. 그러면 서울에 해당하는 태그들이 출력됩니다. 그다음에 서울의 현재기온 25.6과 습도 30도 클릭해봅니다. 이런 방식으로 HTML 코드와 웹 페이지 화면을 보면서 어떤 태그가 원하는 값인지 찾습니다.
▼ 그림 46-19 웹 페이지에서 원하는 값 찾기
이제 HTML 코드를 살펴보겠습니다.
에서 도시(지점)별 데이터는
태그로 묶여 있고, 세부 값은 태그에 들어있습니다. 여기서는 태그 안에 태그가 있으면 지점이라 판단하고, 지점 값을 가져옵니다. 그다음에 기온은 여섯 번째(인덱스 5) 의 값을 가져오고, 습도는 열 번째(인덱스 9) 의 값을 가져오면 됩니다. < table class = "table_develop3" summary = "기상실황표로 지점, 날씨, 기온, 강수, 바람, 기압등을 안내한 표입니다." > … 생략 … < tr > < td >< a href = "/weather/observation/currentweather.jsp?tm=2017.5.17.14:00&type=t99&mode=0&auto_man=m&stn=108" > 서울 < td > 맑음 < td > 18.9 < td > 1 < td > 1 < td > 25.6 < td > 6.7 < td > 70 < td >& nbsp ; < td > 30 < td > 서남서 < td > 2.1 < td > 1010.1 … 생략 …
다시 파이썬에서 HTML을 가져오는 부분입니다. 여기서는 requests 모듈로 웹 페이지의 HTML을 가져오고, bs4 모듈로 HTML을 파싱합니다(HTML 파싱은 텍스트 형태의 HTML 코드를 분석해서 객체로 만든 뒤 검색하거나 편집할 수 있도록 만드는 작업입니다. 그리고 bs4는 BeautifulSoup 라이브러리이고 HTML 코드를 파싱하는데 사용합니다).
import requests # 웹 페이지의 HTML을 가져오는 모듈 from bs4 import BeautifulSoup # HTML을 파싱하는 모듈 # 웹 페이지를 가져온 뒤 BeautifulSoup 객체로 만듦 response = requests . get ( ‘https://pythondojang.bitbucket.io/weather/observation/currentweather.html’ ) soup = BeautifulSoup ( response . content , ‘html.parser’ )
request.get에 URL을 넣으면 응답(Response) 객체가 나옵니다. 그리고 BeautifulSoup 클래스에 응답 객체의 content 속성과 ‘html.parser’를 넣습니다. content 속성에는 텍스트 형태의 HTML이 들어있으며, 파이썬의 html.parser 모듈을 사용해서 파싱하도록 설정합니다.
참고 | 아나콘다를 사용하지 않는다면? requests와 bs4는 기본적으로 파이썬에 포함되어 있지 않습니다. 따라서 pip install requests, pip install bs4로 패키지를 설치해줍니다.
이제 BeautifulSoup 클래스로 만든 soup 객체로 태그를 찾습니다. 먼저 soup.find(‘table’, { ‘class’: ‘table_develop3’ })과 같이 HTML의 class 속성(attribute)이 table_develop3인
태그를 찾습니다(HTML의 class는 태그의 스타일을 지정할 때 사용하는 속성이며 파이썬의 클래스와는 다릅니다).
table = soup . find ( ‘table’ , { ‘class’ : ‘table_develop3’ }) #
을 찾음
그다음에는 데이터를 저장할 리스트 data를 만듭니다. 그리고 for tr in table.find_all(‘tr’):과 같이 table에서 모든
태그를 찾아서 반복합니다. 즉, 이 태그에 서울, 백령도, 인천 등 지점별 데이터가 들어있으므로 반복할 때마다 서울, 백령도, 인천 등 각 지점의 데이터를 가져옵니다. data = [] # 데이터를 저장할 리스트 생성 for tr in table . find_all ( ‘tr’ ): # 모든
태그를 찾아서 반복(각 지점의 데이터를 가져옴) 각 지점의 데이터를 가져왔으면 list(tr.find_all(‘td’))과 같이 tr에서 모든
태그를 찾아서 리스트로 만듭니다. 이렇게 하면 지점, 현재일기, 시정, 운량, 중하운량, 현재기온, 이슬점온도, 불쾌지수, 일강수, 습도, 풍향, 풍속, 해면기압 가 리스트에 들어갑니다. tds = list ( tr . find_all ( ‘td’ )) # 모든
태그를 찾아서 리스트로 만듦 # (각 날씨 값을 리스트로 만듦) 이제
태그 리스트 tds를 반복하면서 각 값을 가져옵니다. 먼저 if td.find(‘a’):와 같이 td에 태그가 있는지 확인합니다. 태그가 있으면 td.find(‘a’).text와 같이 태그의 text속성에서 지점을 가져옵니다(text 속성은 <태그>텍스트에서 태그 안에 들어있는 텍스트를 가져옵니다). 그리고 기온(현재기온)은 여섯 번째(인덱스 5), 습도는 열 번째(인덱스 9)에 있다는 것을 확인했으므로 tds[5].text에서 기온을 가져오고, tds[9].text에서 습도를 가져옵니다. for td in tds : #
태그 리스트 반복(각 날씨 값을 가져옴) if td . find ( ‘a’ ): # 안에 태그가 있으면(지점인지 확인) point = td . find ( ‘a’ ) . text # 태그 안에서 지점을 가져옴 temperature = tds [ 5 ] . text # 태그 리스트의 여섯 번째(인덱스 5)에서 기온을 가져옴 humidity = tds [ 9 ] . text # 태그 리스트의 열 번째(인덱스 9)에서 습도를 가져옴 data . append ([ point , temperature , humidity ]) # data 리스트에 지점, 기온, 습도를 추가 필요한 값을 가져왔으면 data 리스트 안에 [point, temperature, humidity]처럼 값을 리스트 형태로 추가해줍니다.
data . append ([ point , temperature , humidity ]) # data 리스트에 지점, 기온, 습도를 추가
참고 | 웹 페이지 크롤링 지금까지 작성한 웹 페이지 크롤링 코드는 특정 태그가 있는지, 몇 번째에 위치한 태그를 가져온다든지 해서 생각보다 체계적이지 못한 느낌이 듭니다. 왜냐하면 우리가 가져오는 웹 페이지는 데이터를 화면에 보여주는게 목적일 뿐 데이터를 체계적으로 저장하는데는 적합하지 않기 때문입니다. 그래서 주어진 HTML 구성에 맞춰서 만들다 보니 코드가 깔끔하지 않습니다. 즉, 크롤링은 웹 페이지마다 전부 코드가 다르게 나오며 같은 웹 페이지라도 개편이 되면 크롤링 코드를 다시 만들어야 합니다.
46.3.4 데이터를 csv 파일에 저장하기
데이터가 완성되었으니 이 데이터를 파일에 저장해보겠습니다. 방금 data의 값을 출력한 뒤에 코드 셀이 하나 더 생겼을 겁니다. 이 코드 셀에서 다음 코드를 실행합니다(셸이 생기지 않았다면 메뉴의 Insert > Insert Cell Below 실행).
weather.ipynb
with open ( ‘weather.csv’ , ‘w’ ) as file : # weather.csv 파일을 쓰기 모드로 열기 file . write ( ‘point,temperature,humidity
‘ ) # 컬럼 이름 추가 for i in data : # data를 반복하면서 file . write ( ‘{0},{1},{2}
‘ . format ( i [ 0 ], i [ 1 ], i [ 2 ])) # 지점,온도,습도를 줄 단위로 저장
코드를 실행하면 프로젝트 폴더(C:\project)에 weather.csv 파일이 생성됩니다. csv 파일은 Comma-separated values의 약자인데 각 컬럼을 ,(콤마)로 구분해서 표현한다고 해서 csv라고 부릅니다. 여기서는 file.write(‘point,temperature,humidity
‘)처럼 맨 윗줄에 컬럼 이름을 추가하고 그 다음 줄부터는 data를 반복하면서 file.write(‘{0},{1},{2}
‘.format(i[0], i[1], i[2]))와 같이 지점, 온도, 습도를 줄단위로 저장합니다. 이때 콤마와 값 사이에는 공백을 넣지 않고 반드시 붙여줍니다.
weather.csv 파일을 메모장이나 기타 텍스트 편집기로 열어보면 다음과 같은 모양으로 지점, 기온, 습도 값이 저장된 것을 볼 수 있습니다.
weather.csv
point , temperature , humidity 서울 , 25.6 , 30 백령도 , 18.4 , 62 인천 , 20.8 , 54 수원 , 25.0 , 41 … 생략 …
특히 csv 파일을 저장할 때 컬럼 이름은 영어로 지정해줍니다. 영어로 지정하면 나중에 각 컬럼에 접근할 때 df.temperature처럼 속성으로 깔끔하게 사용할 수 있습니다.
So you have finished reading the 웹 페이지 html 추출 topic article, if you find this article useful, please share it. Thank you very much. See more: 웹페이지 긁어오기 프로그램, 웹사이트 통째로 가져오기, javascript 웹 페이지 긁어오기, R html 추출, 자바 스크립트 웹 페이지 긁어오기, 웹페이지 특정 부분 가져 오기, 웹페이지 텍스트 긁어오기, HTML 긁기